CUTLASS CUTE 5 Hopper 特性:tma & wgmma¶
约 1509 个字 77 行代码 2 张图片 预计阅读时间 9 分钟

本文将对 Hopper 中的 tma & wgmma 特性做一个简单整理,并介绍二者在 cute 当中的使用方法
TMA¶
reference blog:
-
Deep Dive on the Hopper TMA Unit for FP8 GEMMs – PyTorch tma tutorial
-
CUTLASS Tutorial: Mastering the NVIDIA® Tensor Memory Accelerator (TMA)
TMA 其实是 Hopper 架构中新引入的硬件单元,其功能是在 global memory 和 shared memory 中传输数据。有了 TMA 过后,有几个优势:
-
能够节省数据传输中的 register(这些 register 通常用于寻址计算),所以 register 可以更多分配给 gemm,以计算更大的矩阵。同时还能再传输数据过程中直接完成 swizzle 计算和简单的 reduction 工作
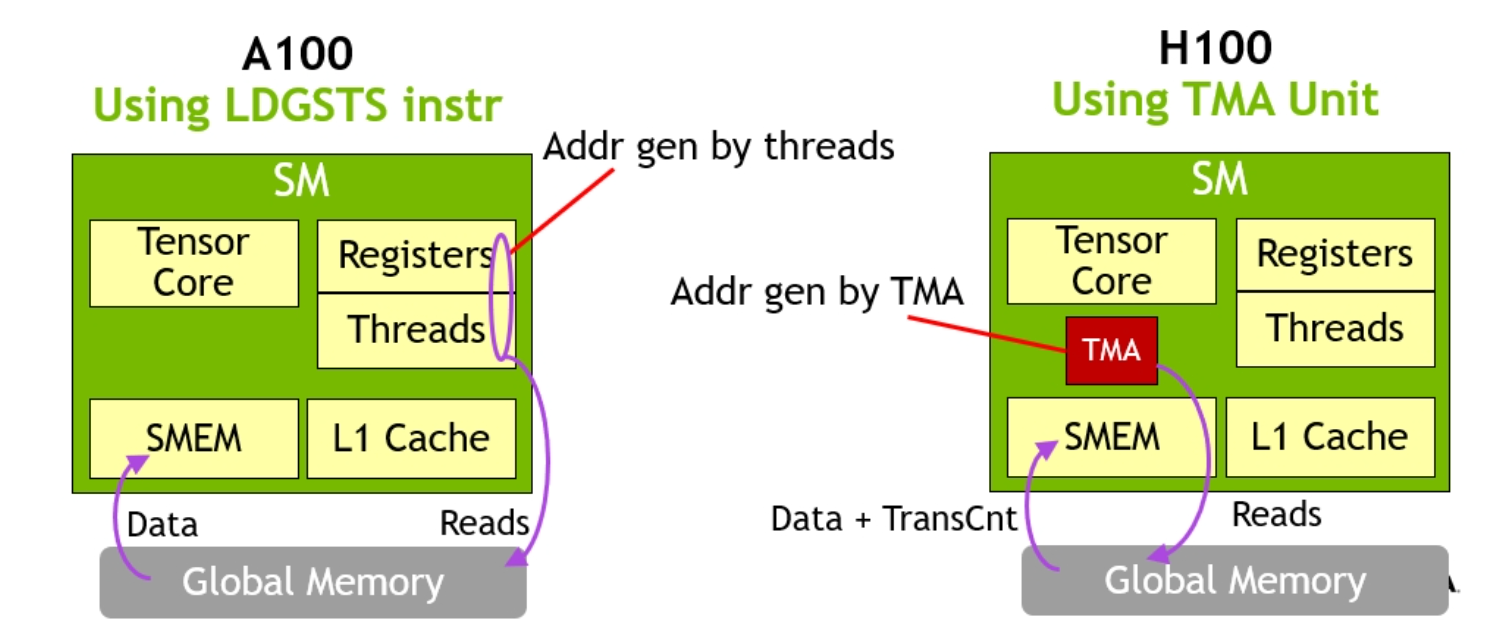
-
能够以单线程发起传输,简化了线程对数据的划分问题,同时也节省了线程资源、register 资源
-
能够自动处理 out of boundary 数据问题
tma descriptor¶
也叫做 CUtensorMap。如前面所述,tma 的功能是 global mem 和 shared mem 之间的数据传输。从 global mem -> shared mem 的传输就是 tma load;反之就是 tma store。不管是 tma load or tma store,都是由 tma descriptor 发起
在 cute 中使用 make_tma_copy 的方式来构建 tma descriptor(实际上是一个 tiled copy 对象),其中有5个重要参数
make_tma_copy(CopyOp const& copy_op,
Tensor<GEngine,GLayout> const& gtensor,
SLayout const& slayout,
CTA_Tiler const& cta_tiler,
Cluster_Size const& cluster_size)
-
copy_op,一共有三种选择:store & load & multicast load,以定义该 copy 功能:是从 gmem -> smem 还是从 smem -> gmem;如果是 gmem -> smem 是否使用 multicast(cluster size > 1) -
gtensor,tensor 在 gmem 当中的表示。 -
slayout,所定义的 smem layout 表示。通常配合cta_tiler以让slayout就是 tma load & store 的 tiler 基本单位,只能以 slayout 的整数倍数据进行 copy -
cta_tiler,每一次 tma copy 的基本单位。通常就是 size ofslayout -
cluster_size,一个 cuteInt,代表 size of cluster layout。如果cluster_size > 1的话,copy_op必须是 multicast load,同时在 load 时,会把数据划分成cluster_size份,每一个 cluster 会 load 各自的数据,最后通过 multicast 的方式共享各自的数据,让每一个 cta 都拥有完整的数据。这个参数似乎只针对 load,对于 store 没有。这个功能在 gemm 会非常有用,例如对于同一列的 cta tile,他们都会共享 B matrix 数据,利用 cluster 内部的 multicast,能够极快地完成数据搬运。另外,表面上该参数非常灵活,实际我只看到了 cluster size 为 1 和 2 两种情况下面简单介绍一下 cluster 的概念
Cluster in Hopper From DeepSeek
线程块集群允许你将多个线程块(Thread Blocks) 组织成一个更大的协作单元。这些线程块可以分布在多个 SM 上,但能保证被并发调度,并且支持高效的跨 SM 协作与数据共享。在传统的线程 (Thread) → 线程块 (Thread Block) → 网格 (Grid) 结构基础上,Hopper 新增了 线程块集群 (Thread Block Cluster) 这一层级,介于线程块和网格之间。运行时设置通过 CUDA 内核启动 API
cudaLaunchKernelEx来配置集群维度。如果 cluster dim 设置为
(x=2, y=1, z=1),对应着在 x dim 上,每两个 cta 构成一个 cluster。通过cute::block_rank_in_cluster();可以直接获得 cta 在当前 cluster 当中的 cluster id
tma load¶
有了 cuTensorMap 过后,可以利用 cute::copy 来进行 tma load,实现 gmem -> smem 的数据传输,命令如下
// tma_load is cuTensorMap
if (is_tma_thread) {
// mbar
__shared__ uint64_t tma_load_mbar; // init of mbar is omitted here
// tma tensor
auto gmem_tensor_coord = tma_load.get_tma_tensor(shape(gmem_tensor));
// cta data slice
auto tma_load_per_cta = tma_load.get_slice(cluster_id);
copy(tma_load.with(tma_load_mbar, mcast_mask),
tma_load_per_cta.partition_S(gmem_tensor_coord_cta),
tma_load_per_cta.partition_D(smem_tensor));
}
可以看到(对比 Ampere copy)有四个显著不一样的地方:
-
mbarrier
tma load 需要传入一个 mbarrier (memory barrier),mbarrier 是 tma 同步的最核心的数据,其被定义在 shared memory 当中。通过 mbarrier 可以来判断:copy 是否能够开始 (empty barrier),以及 copy 是否已经结束 (full barrier)。在上述代码中的
tma_load_mbar充当的就是 full barrier 的角色 -
tma tensor
tma 进行 copy 时使用的是坐标(coordinate)而不是偏移(offset),所以需要有一个专门的 tensor 来表示,通过
get_tma_tensor(shape(gmem_tensor))即可获得。参考 NVIDIA TMA 全面分析,tma 在搬运 tensor 的时候是根据首坐标 + box dim 来确定搬运数据的范围。即以 bounding box 为单位来搬运数据,bounding box 通常就是我们定义的 smem 大小。开发者只需定义“搬什么”,而无需关心“怎么搬”,避免与复杂的物理地址接触。另外 tma tensor 只针对于 gmem 使用,对于 smem 不需要使用 tma tensor 进行构建,可直接使用。tma tensor 与普通 tensor 最大的区别在于其 stride 是一个 vector 而不是一个 scaler
PythonTensor( shape=(M, N), stride=(1, M) ) TMA_Tensor( shape=(M, N), stride=(1@0, 1@1) ) 1@0 = (1, 0) # a vector 1@1 = (0, 1) # layout function Tensor(1, 2) = 1 * 1 + 2 * M # TMA layout function Tensor(1, 2) = 1 * (1, 0) + 2 * (0, 1) = (1, 2)其中
x@y意味着数字 x,在向量中的第 y 个位置,向量的维度等于 shape 的维度。此时 layout function 的输出变成了一个 vector,也就是我们需要的坐标。这也是make_identity_layout的原理 -
get slice
在 Ampere 架构时,我们传入的是 thread id,从而通过
partition_S/D获得每个线程应有的数据。而这里传入的是 cluster id,也是通过partition_S/D获得每个 cluster 应有的数据。如果 cluster size = 1 的话,说明没有 multicast,每一个 cta 所获得的都是完整的数据;反之 cluster size > 1 的话,一个 clustere 内的各个 cta 将获得部分数据 -
mcast mask
这也是为了配合 cluster multicast 所设计的,我们可以选择 cluster 内的哪些 cta 参与到 multicast 的过程当中,只有选中的 cta 才会将数据进行共享。该 mask 是一个 bit mask,总共为 16-bit,值为1则为参与,反之不参与。通常所有的 cluster 都会共享自己的数据,所以 mcast mask 的设置也相对固定,直接设置为
(1 << size(cluster_layout)) - 1
tma store¶
tma store 的使用和 tma load 类似,其功能是将数据从 smem copy 到 gmem,但是同步和 tma load 有显著区别。
// cuTensorMap is tma_store
if (is_tma_thread) {
// tma tensor
auto gmem_tensor_coord = tma_store.get_tma_tensor(shape(gmem_tensor));
// cta data slice
auto tma_store_per_cta = tma_store.get_slice(cluster_id);
copy(tma_store,
tma_store_per_cta.partition_S(gmem_tensor_coord_cta),
tma_store_per_cta.partition_D(smem_tensor));
// commit
tma_store_arrive();
}
// wait latest 0 commit
tma_store_wait<0>();
可以看到 tma store 和 tma load 都需要 tma tensor & slice 操作,但是不需要 mbarrier 来进行同步。其使用的是 tma_store_arrive 和 tma_store_wait 来进行同步操作,这里类似 Ampere 中的 async copy 同步 cp_async_fence & cp_async_wait,对 copy 操作进行 commit 和 wait
wgmma¶
CUTLASS Tutorial: Fast Matrix-Multiplication with WGMMA on NVIDIA® Hopper™ GPUs – Colfax Research
CUTLASS Tutorial: Efficient GEMM kernel designs with Pipelining – Colfax Research
基本特点¶
一个 warp group 是由 4 个连续的 warps 构成,i.e. 128 个连续的线程。而 wgmma 就是由一个 warp group 协作执行的 mma,其支持更大的矩阵分块计算。wgmma 有几个特点:
- 矩阵形状:基本计算形状为
m64nNk16,其中 N 可以是 8 的倍数,范围从 8 到 256 - 异步执行:遵循异步的 consistency model,wgmma 不遵循 cuda 代码当中的 program order,和 Ampere mma 不同的是,需要使用额外的 fence 操作来保证 mma 执行的顺序在 smem 完成写入之后。这种异步执行的操作都是在 async proxy 中完成的,tma operations 也是
- 操作数存储:操作数矩阵 B 必须存储在共享内存(SMEM) 中。操作数矩阵 A 可以位于共享内存或寄存器内存(RMEM)中,而累加器矩阵 C 则始终保存在寄存器中
- 数据类型支持:WGMMA 支持多种数据类型,包括 FP16、BF16、TF32、FP8(E4M3 和 E5M2 格式)以及整数格式(如 U8/S8),并在 FP32 或 FP16 中进行累加。wgmma 没有 4-bit 运算单元,即:不支持 fp4/int4 的矩阵运算
如何构建¶
SM90 MMA atoms 在 cute 中都标记为 SM90_MxNxK_XYZ_SS or SM90_MxNxK_XYZ_RS
XandY是操作数的数据类型Z是累加器的数据类型MxNxK是计算 mma 的 tile 大小,M 始终是 64,N 是 8~256 的任意 8 的倍数,K 是 32 bytes 对应的数据类型的个数,例如 fp16 mma 则 K 是 16
wgmma 的构建和 mma 的构建是类似的,都有 AtomLayoutMNK and PermutationMNK
TiledMMA tiled_mma = make_tiled_mma(
SM90_64x64x16_F16F16F16_SS{},
Layout<Shape<_2,_1,_1>>{} // AtomLayoutMNK, cooperatively complete a bigger mma
// PermutationMNK is barely used
);
除此之外 wgmma 会对 smem 的 swizzle 形式有特殊要求。以 K major 为例(MN major 也是类似的),只有4种合法的 smem swizzle layout
Layout_K_INTER_Atom_Bits = ComposedLayout<Swizzle<0,4,3>, smem_ptr_flag, Layout<Shape<_8, _128>,Stride< _128,_1>>>;
Layout_K_SW32_Atom_Bits = ComposedLayout<Swizzle<1,4,3>, smem_ptr_flag, Layout<Shape<_8, _256>,Stride< _256,_1>>>;
Layout_K_SW64_Atom_Bits = ComposedLayout<Swizzle<2,4,3>, smem_ptr_flag, Layout<Shape<_8, _512>,Stride< _512,_1>>>;
Layout_K_SW128_Atom_Bits = ComposedLayout<Swizzle<3,4,3>, smem_ptr_flag, Layout<Shape<_8,_1024>,Stride<_1024,_1>>>;
// K-major layouts in units of Type
template <class Type>
using Layout_K_INTER_Atom = decltype(upcast<sizeof_bits<Type>::value>(Layout_K_INTER_Atom_Bits{}));
template <class Type>
using Layout_K_SW32_Atom = decltype(upcast<sizeof_bits<Type>::value>(Layout_K_SW32_Atom_Bits{}));
template <class Type>
using Layout_K_SW64_Atom = decltype(upcast<sizeof_bits<Type>::value>(Layout_K_SW64_Atom_Bits{}));
template <class Type>
using Layout_K_SW128_Atom = decltype(upcast<sizeof_bits<Type>::value>(Layout_K_SW128_Atom_Bits{}));
可以看到这些 layout 都是以二维的形式存在,第一个 mode 固定为 8,第二个 mode 代表了数据 bits 数量,即:其要求 K 维度的大小必须是 multiple of 16/32/64/128 bytes。我们会根据 smem K 维度的大小来选择最大的 swizzle layout。例如一块 smem 用于存储 (M, K) 大小的 fp16 矩阵:如果 K 个 fp16 是 128 bytes 的整数倍,那么选择 Layout_K_SW128_Atom;如果 K 个 fp16 是 64 bytes 的整数倍,那么选择 Layout_K_SW64_Atom,以此类推
如何使用¶
在 cute 当中使用 sm90 wgmma 类似于 sm80,都需要经历相同的三部曲:slice to thread mma + partition fragments + gemm,但是略有一些区别
-
根据 thread id 构建
thr_mma由于 wgmma 会直接从 smem 当中获得数据,那么每一个 thread 所分配的数据其实都是一样的,参考 WGMMA Fragments and Descriptors 小节。所以我们会在一些代码中看到使用 warp group id 来获得
thr_mma在编程中我遇到了另外一个问题:我们会使用 warp specialization 的方式进行编程,其中 producer warp group 是不会参与 mma 计算的,那么如果 producer warp group 是 wg0,而 mma warp group 为 wg1,此时我们在 get slice 时应当选择 0 还是 1 呢?应该选择
get_slice(0)。因为tiled_mma对象并不会感知到其属于哪个 warp group,或者外部还有其他多少 threads / warp group,其只在乎自身所定义了多少 threads / warp group。所以我们在get_slice(x)时,其实是在对 tiled mma 内部所定义的 threads / warp group 进行切分 -
构建 fragments
在 sm80 当中
partition_fragments_A/B/C实际上是在构建 register 用于存储 smem 中的数据以进行 mma 计算。但是 sm90 wgmma 直接从 smem 当中获得数据,那这个 fragments 又是什么呢?同样在 WGMMA Fragments and Descriptors 小节当中获得了解答,这是一个 matrix descripter,虽然其本质也是 regsiter,但并不是用于存放数据,而是用于描述数据在 smem 当中的位置,可以直接传给 wgmma 使用,而不需要进行 smem -> register 的搬运 -
利用
cute::gemm完成矩阵运算不过由于 wgmma 的异步特性(async proxy),我们一般不会简单使用上面这一行
cute::gemm,而需要一些同步语句来控制:- 用于避免 wgmma 乱序执行的 fence
warpgroup_arrive(),(从经验上看)这个 fence 必须在每一次使用 wgmma 之前使用,可认为是一个定式 - commit batch & wait 机制用于控制异步流水线
- 用于避免 wgmma 乱序执行的 fence