SPG & BtcDet
Xu, Qiangeng, et al. “SPG: Unsupervised Domain Adaptation for 3D Object Detection via Semantic Point Generation.” ArXiv:2108.06709 [Cs], Aug. 2021. arXiv.org, http://arxiv.org/abs/2108.06709.
Xu, Qiangeng, et al. “Behind the Curtain: Learning Occluded Shapes for 3D Object Detection.” ArXiv:2112.02205 [Cs], Dec. 2021. arXiv.org, http://arxiv.org/abs/2112.02205.
这两篇论文有着非常相似的思路,它们都是从点云的稀疏性出发,尝试在场景当中生成前景点,或者在特征图谱中融合前景点存在的概率
SPG
Abstract
论文首先提出了问题:domain shifts,也就是说数据集之间,样本的分布是有差异的。有的点云样本密度较大,而有的点云采集可能由于天气的原因,密度较小。使用检测器在点云较少的场景中进行预测,表现将会大大降低
论文提出解决方法:Semantic Point Generation (SPG),使用轻量级神经网络在相关场景 (generation area) 中生成前景点,以补偿点云消失的部分
Domian gap
在我理解 domain gap 就是在于数据集分布的差异。在看论文的时候看到了 feature misalign 问题,这里也总结一下:
- 多尺度问题。一个特征点对应了多个尺度,该问题可以使用 FPN 解决,有一种分治的思想在里面,小目标使用高分辨率特征,大目标使用低分辨率特征
- anchor & 分类得分不匹配。可以通过 RCNN 的细化解决
- 遮挡。无法解决这样的问题
除了使用特征对齐的方法,还有的论文将数据从一个域转到另一个域,本文也应该受到该方法的启发
另外还提到了使用对抗生成网络来解决的方法,不过没有深入
Semantic Point Generation
定义原始点云输入
F,代表其他的原始特征,例如反射强度。将点云场景进行体素化,对于每一个体素,都将生成一个置信度 $\tilde P^f$ 以及一个特征 $\tilde \phi$ ,前者表示该体素有前景点的概率,后者表示该点的特征 $(x, y, z, f)$
虽然对每一个体素都进行了预测,但并不是所有的体素都参与生成点云。需要满足两个条件:
- 在生成区域内的体素 generation area。生成区域定义为原始非空体素附近的区域
- 置信度大于阈值的体素
SPG trainning targets
前面对于 SPG 的目的已经介绍了一部分。标签这部分比较简单,就是使用了原始点云中的非空体素以及在选框内的体素作为前景体素标签,进行训练
Model structure
模型是基于 PointPillars,不过在最后将 Pillars 还原成为了体素,进行了两部分的预测
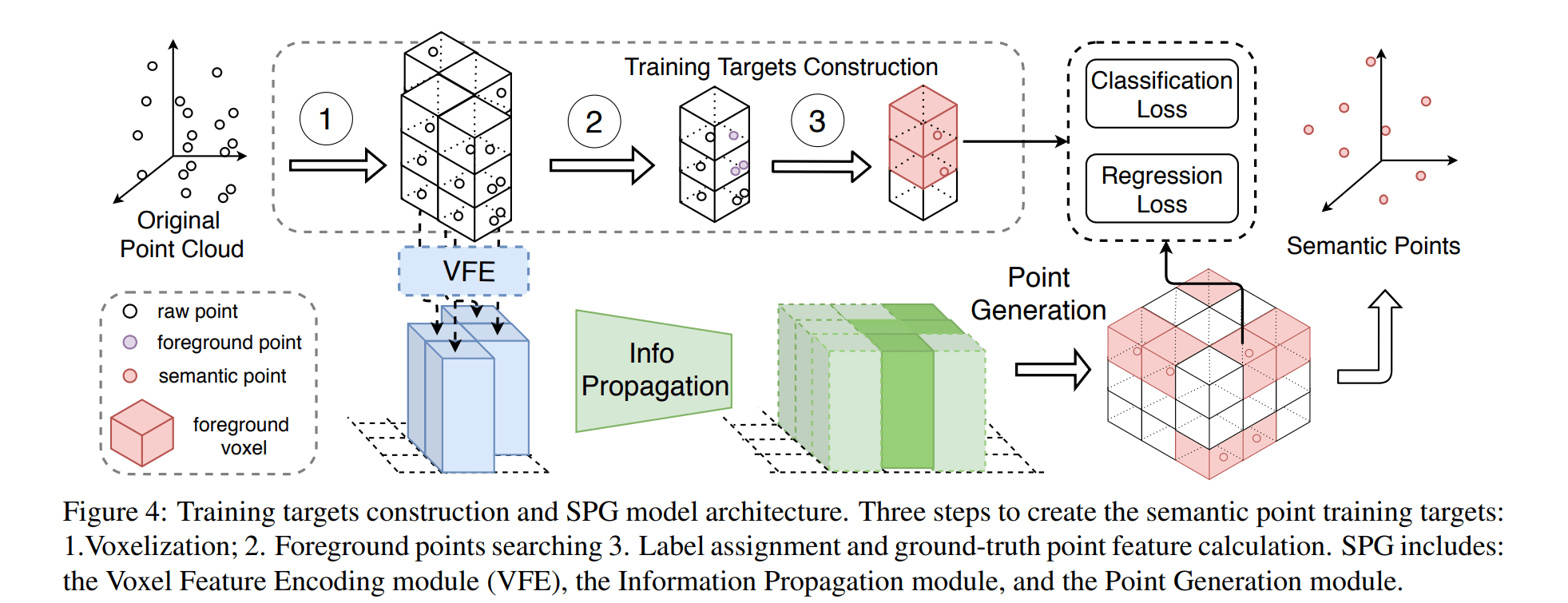
Hide and predict
这是论文中的一个训练策略:将一部分的体素移除,但是其标签仍然保持。这样天然形成了一些空体素,希望网络去学习生成点
个人认为,这里仍有改进空间:这并没有明确让网络去学习稀疏 -> 密集这样的一个过程。仅仅是简单的下采样,不能够模拟出点云中的稀疏场景,更难以表达稀疏特征和密集特征之间的关系。当然这样的操作肯定是对网络有益的,增加了 robustness
Loss functions
对于分类的损失函数,需要特殊处理的有两部分:1. $V_e^f$ empty foreground voxel; 2. hidden voxel 给它们加上了不同的权重即可。其他的 observed voxel & empty background voxel 照常处理
对于回归的损失函数,仅对 observed voxel & hidden voxel 做回归损失
其中 $\alpha = 0.5, \beta =2.0$,并且所有的体素都必须是 generation area 之内的体素
Experiments
训练是在 Waymo Open Dataset 上训练的,并在 Waymo Open Dataset & KirK 上都进行了测试
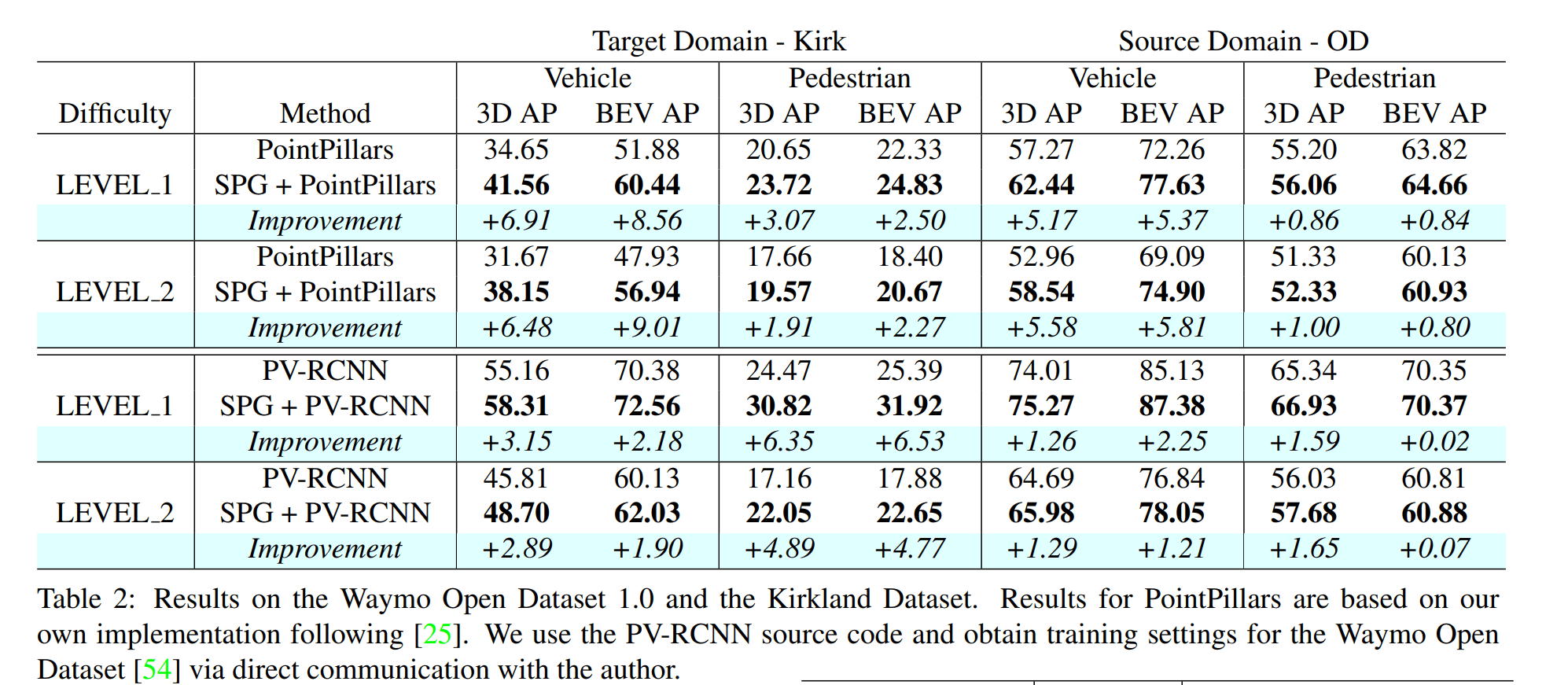
在 KITTI 测试集上也进行了实验
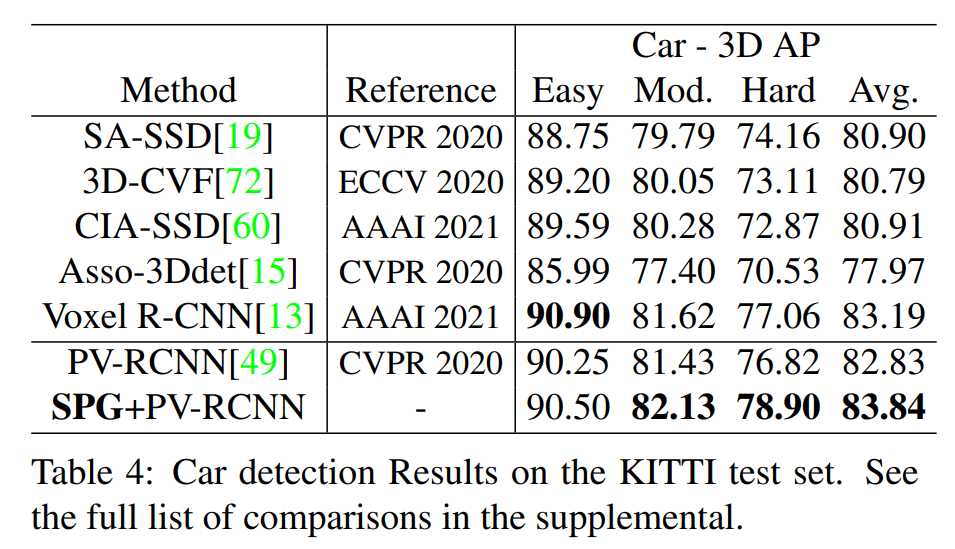
KITTI 验证集
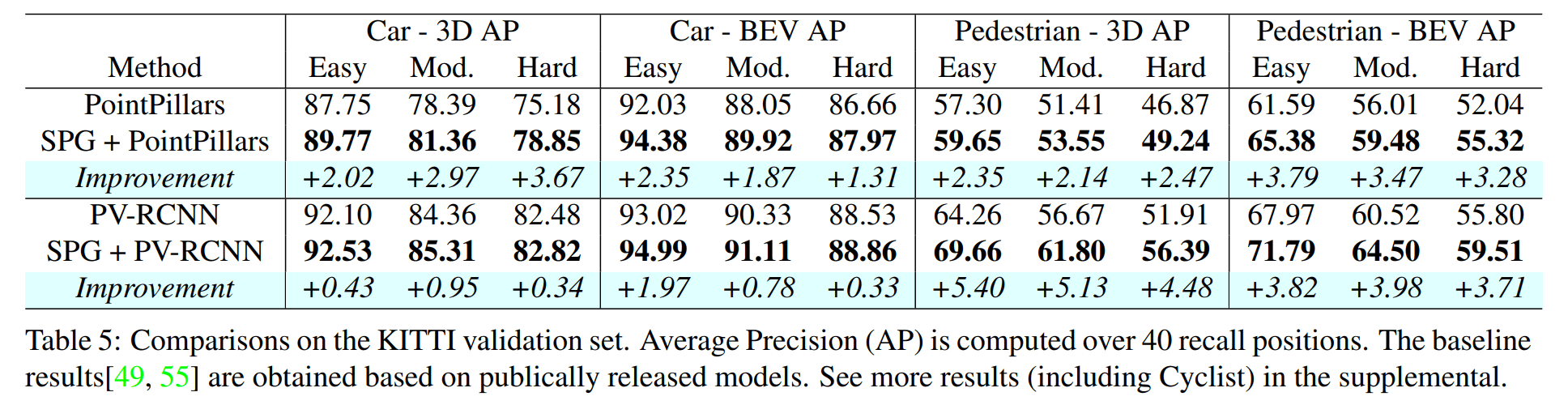
SPG 与各种策略的比较

其中 k-frames 是将 k 帧点云进行叠加,也是一个稳定涨点技巧但是需要大量的内存和处理时间。SPG 很轻量,只加入了 8k 个点,并且参数少速度快
BtcDet
这篇论文相对于 SPG 感觉更晦涩更细致,但是出发点依然是对于消失点云的补偿。本文更进一步对消失点云以及消失形状进行学习
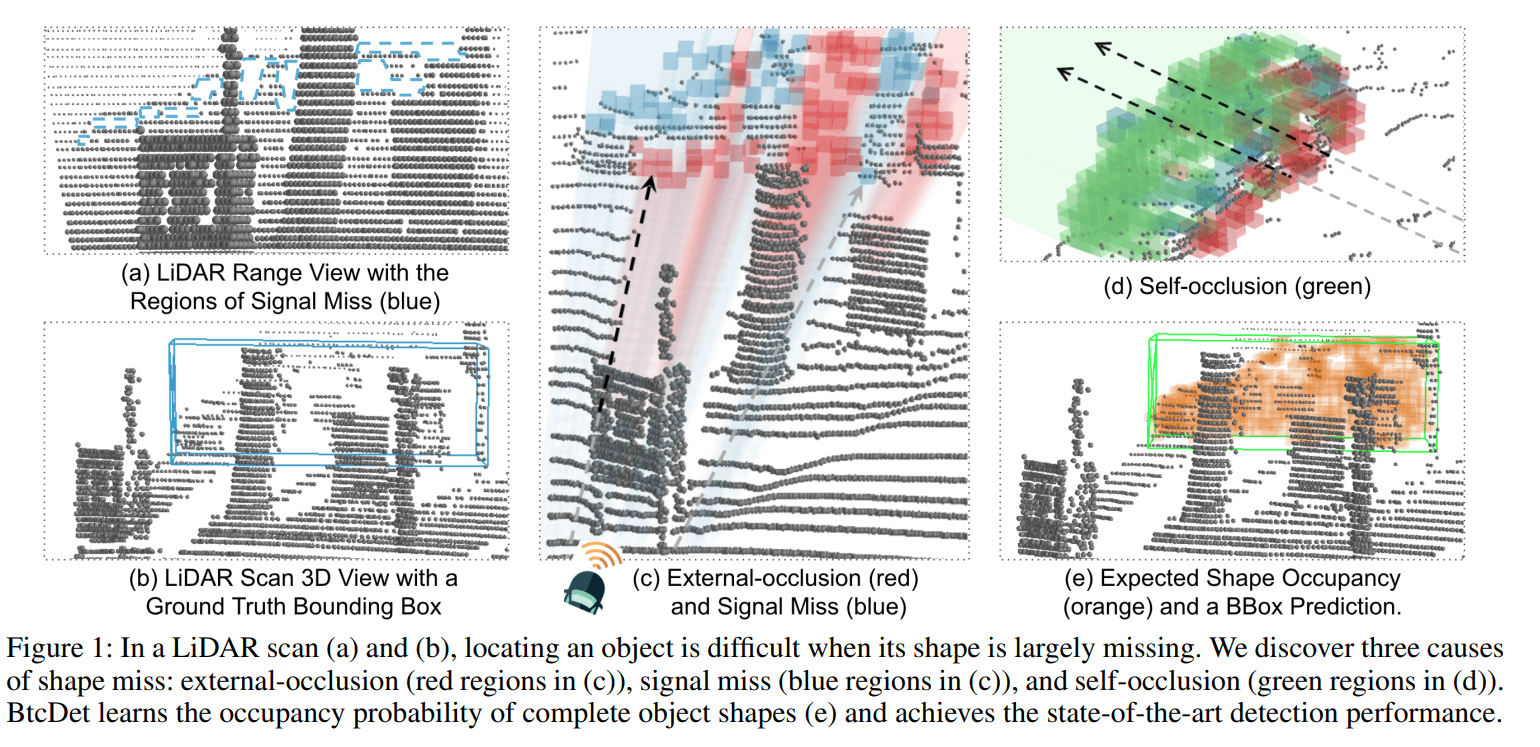
Causes of shape miss
- Signal miss,信号消失。这里我理解为激光穿过了玻璃类似的物质,或者反射角太大,或者被物质吸收,没办法进行返回
- Occlusion,遮挡。后方物体被前方物体遮挡
- 信号发散。这是点云自身特点造成,越远处的地方,点云将越稀疏
论文指出,在点云密集的地方,现在的 SOTA 检测器能够非常非常精准地识别出来,这也是对点云补偿的出发点
Learning shapes for 3D object detection
在之前的论文如 SA-SSD & PV-RCNN 已经证明学习结构信息(前景点分割,中心点预测)对于目标检测是有提升的。但是它们忽略了消失形状的影响
Learning shapes in occlusion
Approximate the complete shapes
首先我们得知道完整的形状是什么样的,这样才能更好地学习。论文采取的策略有两个
镜像。因为大多数目标都是镜像对称的,对称将补充部分点云
向其他同类 object “借”。论文构造了一个函数 $H(A,B)$ 来评估B 物体是否尽可能补全 A 物体
第一项希望 B 的点尽量覆盖 A 的点
第二项希望二者的 IoU 尽量大
第三项希望 B 中的 voxel 尽量多的不属于 A
启发式函数越低越好,代表 B 更能覆盖和填补 A。对 A 物体,选择得分最高的3个物体,并将它们的点云借给 A 作为补充
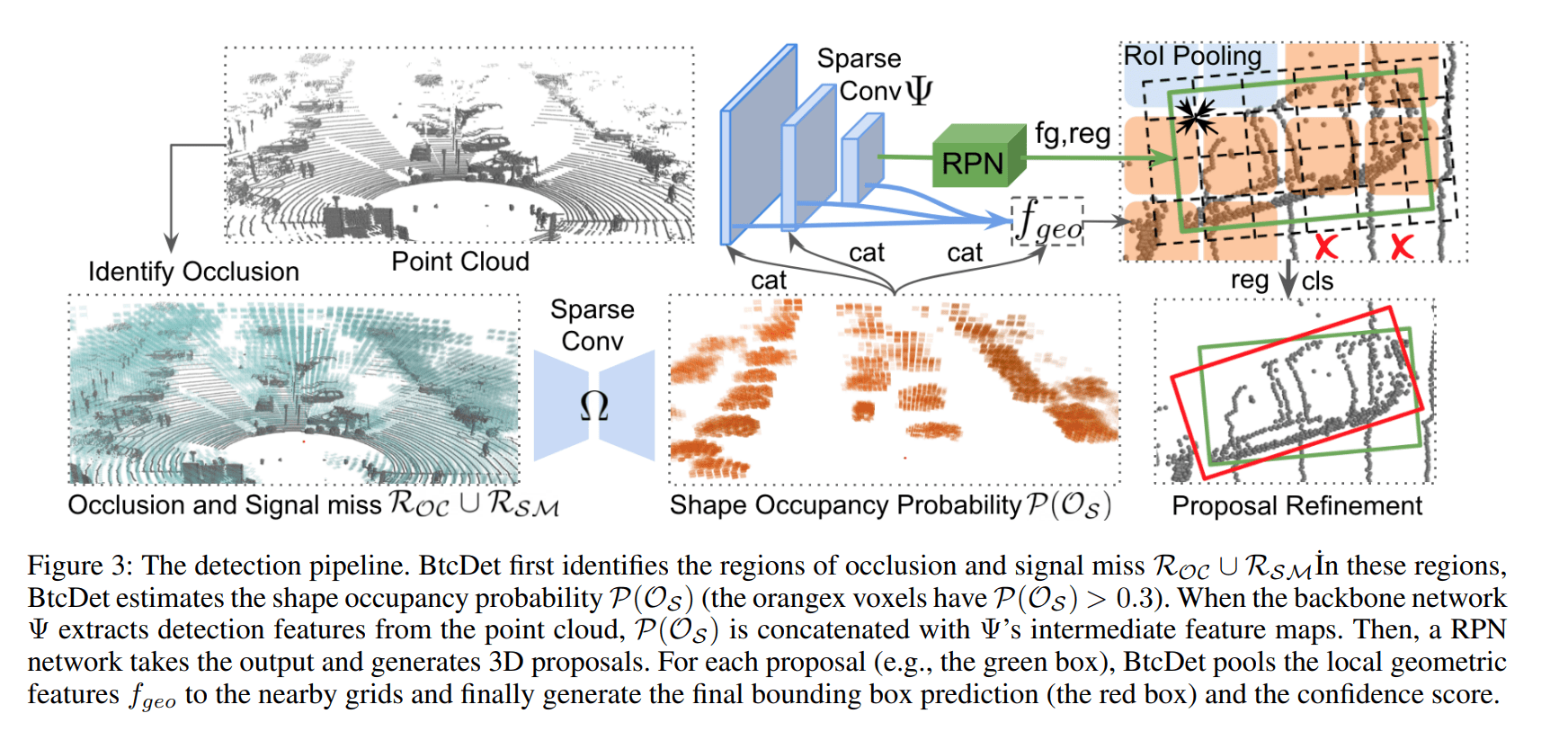
Identify $R_{oc} \cup R_{sm}$ in spherical coordinate
这个极坐标系也是本文有点难以理解的。对于 occlusion 区域,是指某个非空弧形体素及其之后的弧形体素区域。对于 signal missing 区域需要使用 range view 来理解。理论上来讲 Lidar 的 range view 应该是铺满整个平面的,但由于 signal missing,range view 会缺失。如果 spherical voxel 映射到缺失区域中,就认定该 spherical voxel 属于 signal missing 区域
Training targets
此时 targets 就不是简单的使用原始点云场景了。而是使用经过目标补全的点云场景
Estimate the shape occupancy
BtcDet 将预测在遮挡和消失区域的 spherical voxel 含有点云的概率。它不作任何的点云生成,这也是与 SPG 的一个区别。SPG 关注的是在空体素处是否含有前景点(在 bbox 中即可),而本文关注的是在遮挡和信号消失的区域是否含有目标点(更精细)
损失函数如下,仅关注遮挡和信号消失的区域
对于借来的点以及空的 voxel 都使用权重 δ
还值得提到是,论文使用的是极坐标系下的 3d 稀疏卷积来提取每一个体素的特征
Shape Occupancy Probability Integration
得到了一个 spherical coordinate feature map $P(Occupancy)$,表示了各个弧形体素中是否包含目标点
先把极坐标系转换到笛卡尔坐标系,这样方便和其他特征图谱进行融合,通过下采样可以得到和其他特征图谱相同分辨率
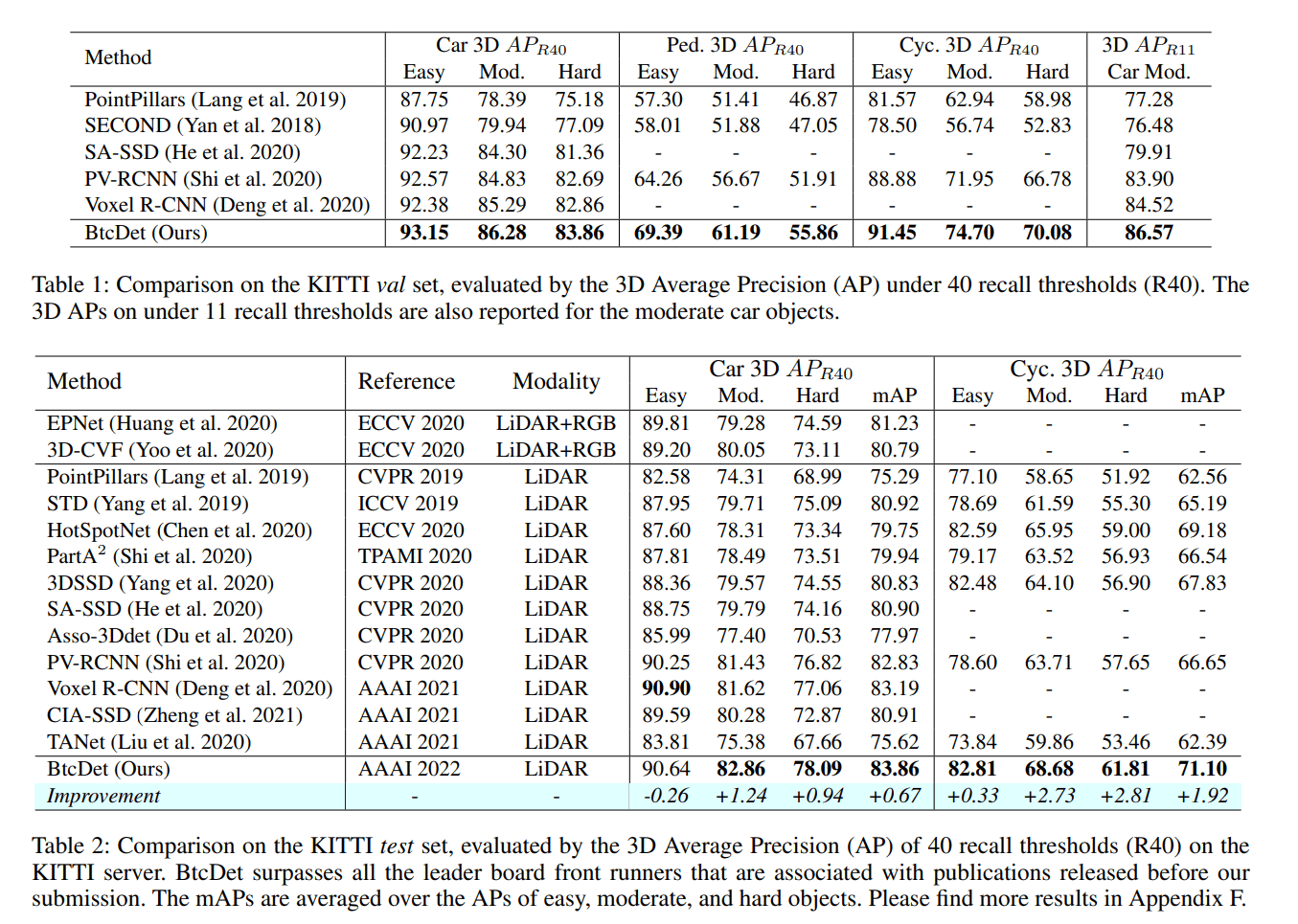
Experiments
在 KITTI 数据集上横扫
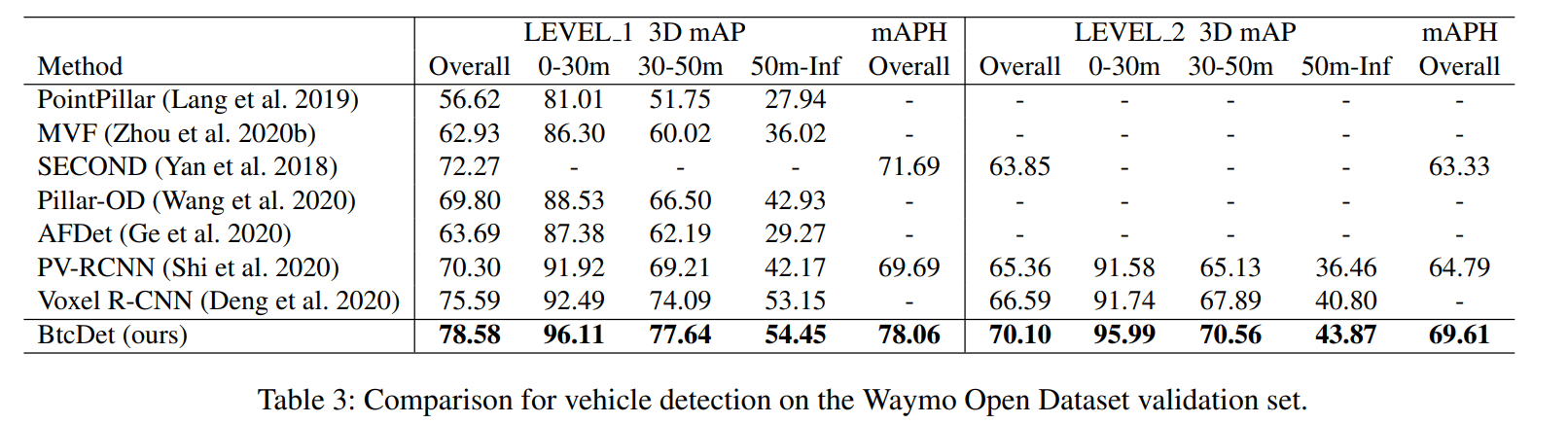
在 waymo 数据集上横扫