Offboard 3D Object Detection from Point Cloud Sequences
Qi, Charles R., et al. “Offboard 3D Object Detection from Point Cloud Sequences.” ArXiv:2103.05073 [Cs], 1, Mar. 2021. arXiv.org, http://arxiv.org/abs/2103.05073.
Yang, Bin, et al. “Auto4D: Learning to Label 4D Objects from Sequential Point Clouds.” ArXiv:2101.06586 [Cs], Mar. 2021. arXiv.org, http://arxiv.org/abs/2101.06586.
这两篇文章都是为了自动标注而设计。不吝惜计算资源,目的就是要把准确率给冲上去,一旦超越或接近了人工标注的水平,这些计算代价相比于人力将会显得更便宜,可用于训练 data-hungry 模型
Auto4D
中心思想都是使用多帧点云来优化当下的预测
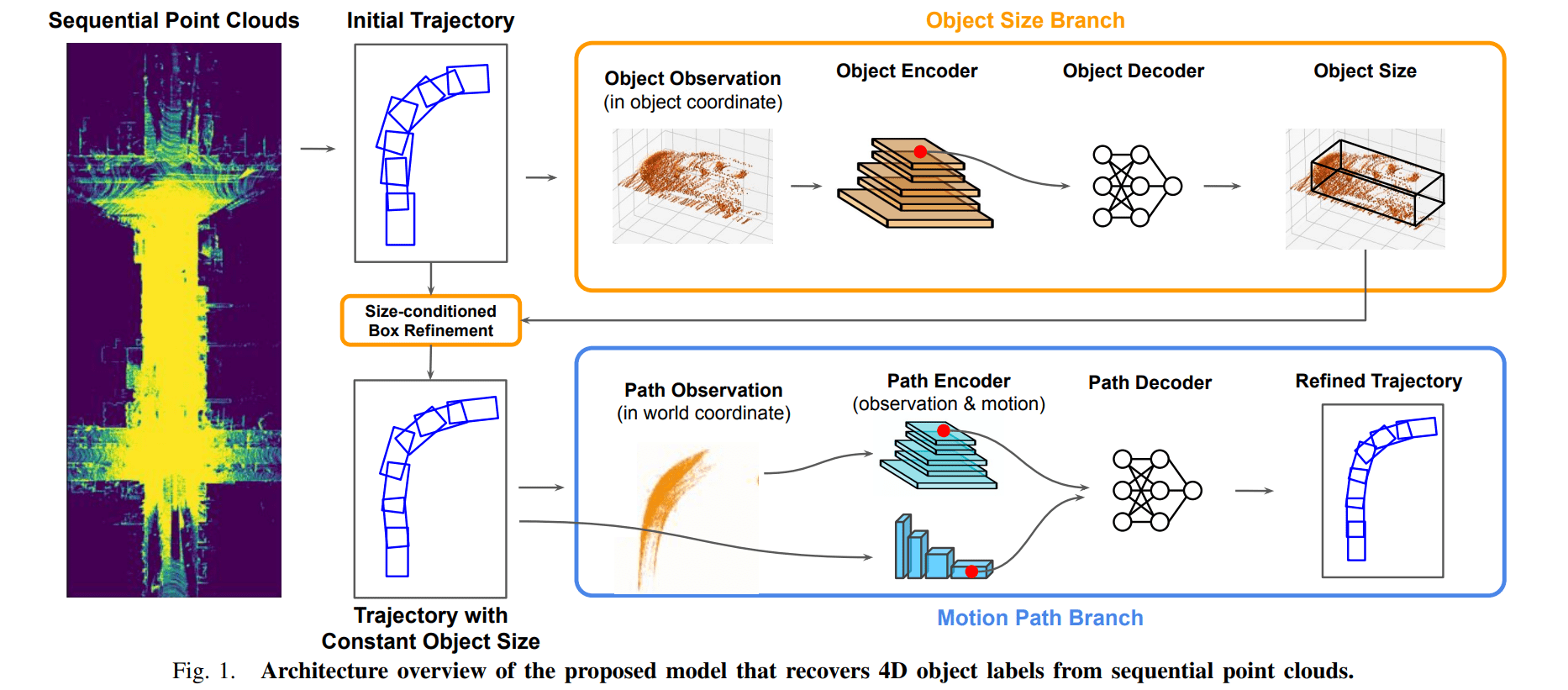
生成预测选框。使用一个现成的点云目标检测器,对(连续)多帧的点云进行检测,形成最初的轨迹预测。轨迹表示为 $O =\set {D_i}$ 其中 D 就代表 detections,与之前的选框表示不同,这里预测选框结果为 $D_i = (p,s,t)$ , $p=(x, y, \theta)$ 代表位置,$s=(w,l)$ 代表选框长宽,$t$ 自然就是时间戳了
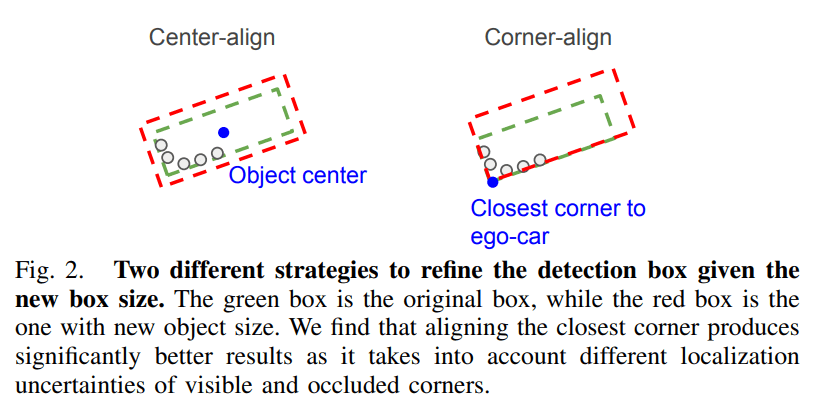
目标大小预测 object size branch。将轨迹中每一个目标的点 $x_{box}^O$ 整合到同一个坐标系 object coordinate(这一步应该需要目标跟踪的算法,以后再总结,假设咱会了,先拿来用😎)。通过一个 encoder & decoder 架构预测出每一个目标的大小,使用该大小去更新轨迹中的选框。对于更新方法论文提出了一个向近侧角对齐的方法,所谓近侧角就是离自车 ego-car 近的那一个角
通过轨迹信息细化选框 motion path branch。这里就不再像上一步使用 object coordinate,而是使用 world corrdinate 将所有的目标中的点 $x_{box}^O$ 整合到同一个坐标场景中,获得轨迹 trajectory,论文里也叫 path。path 的特征包含两个部分:轨迹 $x_{path}^O$(绝对特征)和位移 $h_{motion}$(相对特征)。其中轨迹特征就是使用点特征,而位移特征是前后帧之间的选框位置的偏移
使用上面两个特征去细化之前预测得到选框
对于静态和动态的物体论文还做了简单的区分处理:静态的物体因为没有轨迹,所以只对得分最高的那一帧进行细化
下面看看图示吧,还是比较清晰的
Offboard 3D Object Detection, Waymo
这一篇是 waymo 的工作,出发点依然是利用连续多帧信息来提高检测表现,然后疯狂叠加 trick,能涨点的全部都给我上,细节很多,最终效果甚至可以接近人类标注。参考链接:知乎
Overview
基本套路都是一样的
- 首先和 Auto4D 一样,使用检测器对多帧进行检测,相当于初始化目标位置
- 将多帧中的目标信息抽取出来(包含点云信息,检测框信息,时间信息)
- 使用这些信息提出高质量选框(此处省略大量细节…)
Problem Statement
- 考虑点云序列 $\set {P_i \in \mathbb R^{n_i \times C}}, i=1,2,…,N$,C 为点云原始特征如 (x, y, z, r)
- sensor poses $\set{M_i=[R_i|t_i] \in \mathbb R^{3\times 4}}$,是已知的。该矩阵用于表示传感器在绝对坐标下的状态,用于消除自车运动的影响
Frame-centric to Object-centric
直接将多个 frame 进行叠加并不能补偿我们关心对象中的点云,所以很自然就引出了 object-centric 叠加方式。也就是我们是对每个物体在多帧里面的点云进行叠加
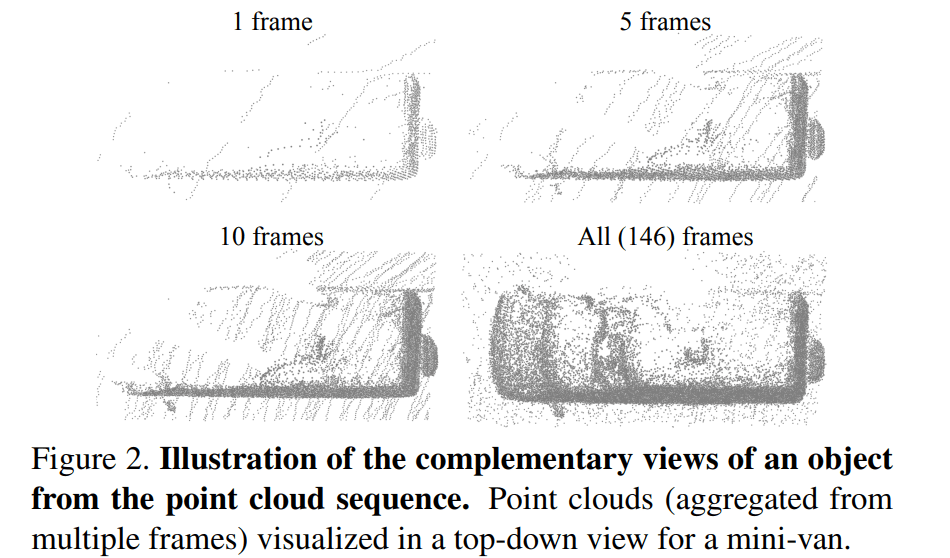
整个流程的示意图如下(现在可能暂时看不明白,可以一会儿倒回来看)
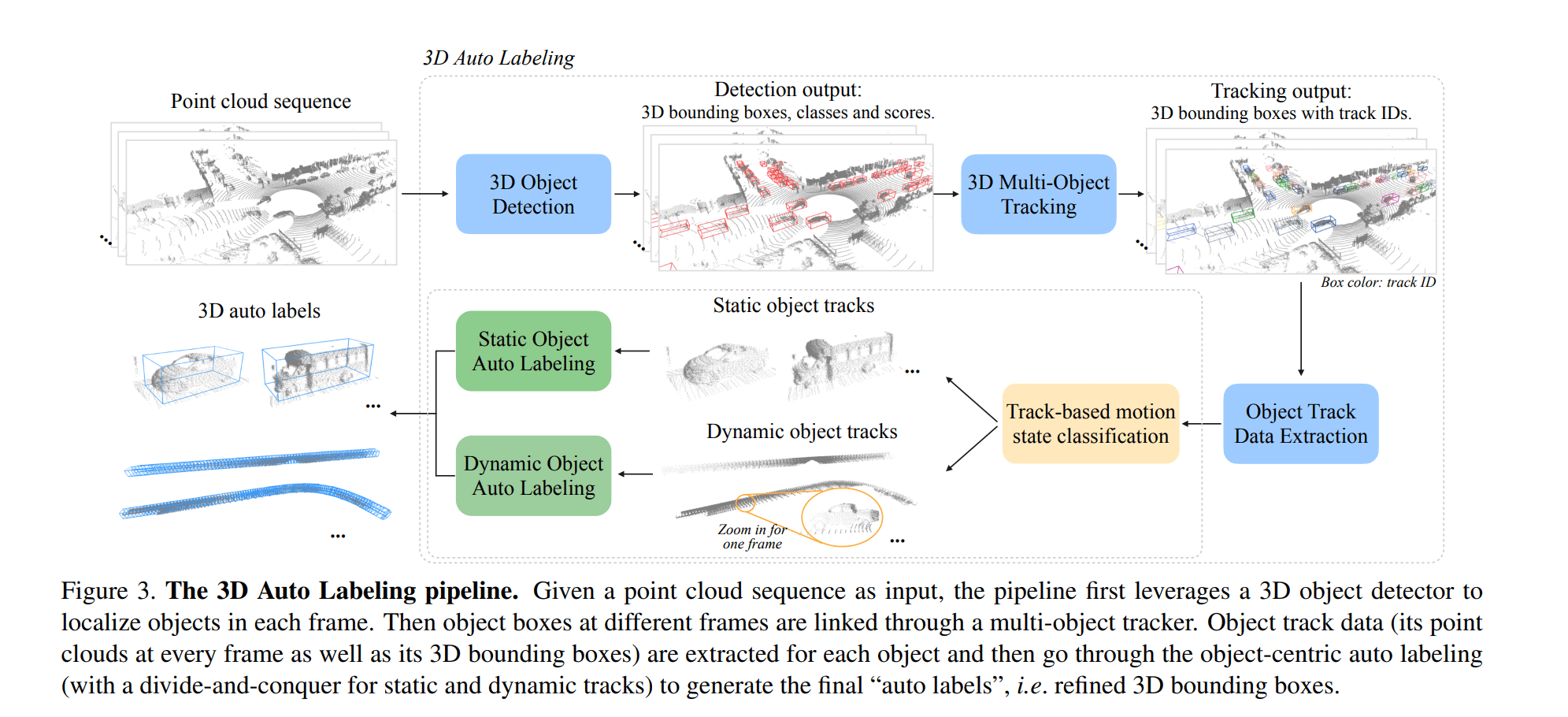
Multi-frame 3D Object Detection
论文提出 MVF 的升级版,MVF++,改变如下:
- 辅助模块用于语义分割 auxiliary segmentation
- 放弃 anchor-based 结构采用 FCOS (还没看过这篇😭)中的 anchor-free
- 增大模型的参数
图示如下(本来又可以发一篇论文,大佬直接几句话带过,然后把详细内容放附录…)
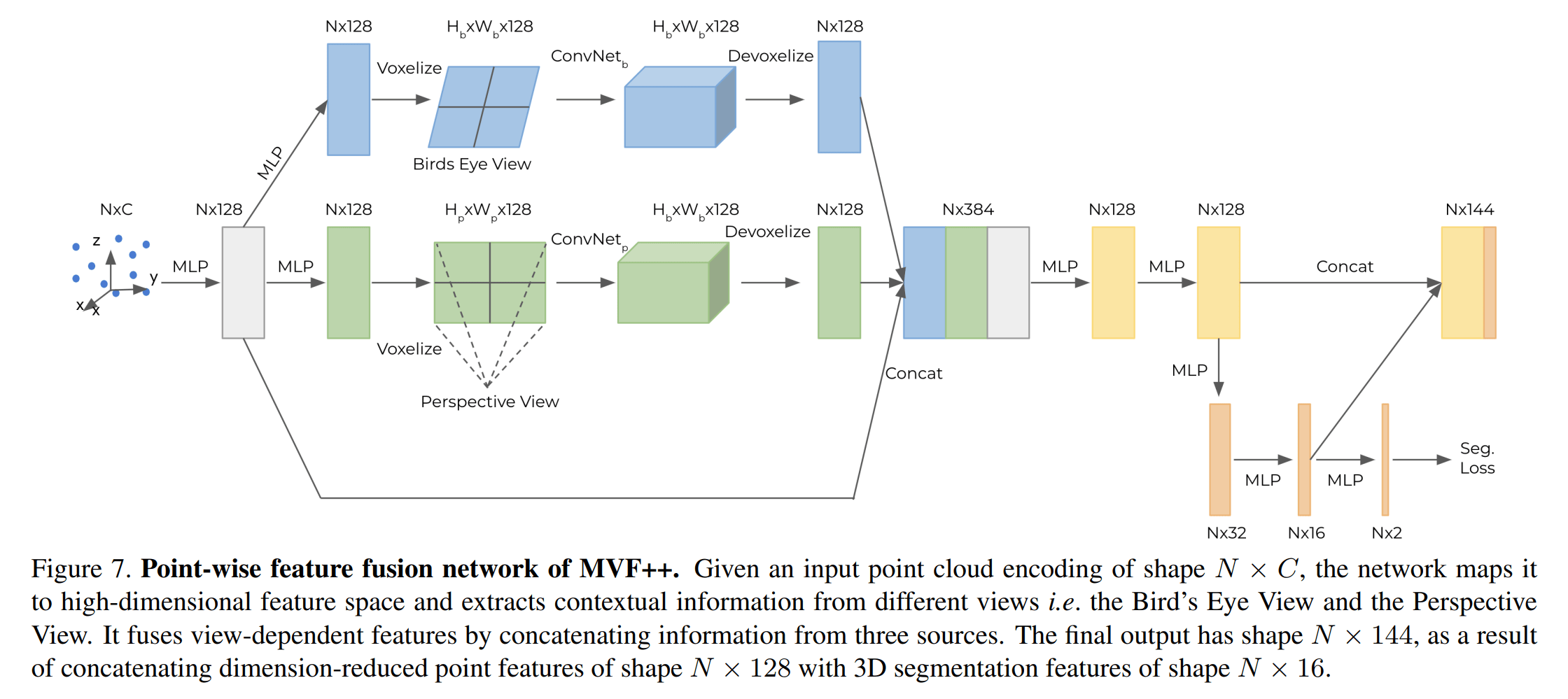
论文直接将多帧的点,基于自车运动 ego-motion,转移到当前帧里,并且每一个点加入了相对的时间戳。这个聚合的点云场景将作为输入,送至 MFV++ 中
Test Time Augmentation
除此之外使用 TTA 设置:将点云场景旋转10种角度,并将获得的预测选框结果进行加权融合
Multi-object Tracking
论文的跟踪算法是 AB3DMOT 的一个变体(或者说简化版?)用检测框做数据关联,卡尔曼滤波做运动状态估计
Object Track Data Extraction
对于每一个独特的目标,将它的多帧检测框以及框内的点提取出来(检测框会稍微放大一点以保留更多信息),用 $\set {P_{j,k}} , \set {B_{j,k}}$ 分别表示第 k 帧,第 j 个物体的点云和选框信息
Object-centric Auto Labeling
现在终于可以进行核心的自动标注部分了。自动标注过程主要由三个子模块完成:
- Track-based motion state classification,估计物体的运动状态,看物体是静止的还是运动的
- Static object auto labeling,静态物体自动标注
- Dynamic object auto labeling,动态物体自动标注
还有一个要提的点:论文为静态物体分配一个单一的 3D bounding box,而不是在不同的帧中分配单独的 boxes,这样能避免抖动
对于连续帧小于7帧的物体,论文不对其进行自动标注,(个人猜测)就直接拿 MVF++ 里的结果作为最终结果
State Classification
对每个目标提取两个特征:检测框中心的方差和跟踪框中心从开始到结束距离,然后用一个线性分类器估计运动状态。标签制作方法如下:如果目标中心点的偏移速度小于1m/s.且开始到结束的距离不超过1m,则认为是静态目标;否则认为它是动态目标。而对于行人,一律作为动态处理
该分类器对于车辆准确率高达 99% 以上,只有一些遮挡很严重的情况识别错误
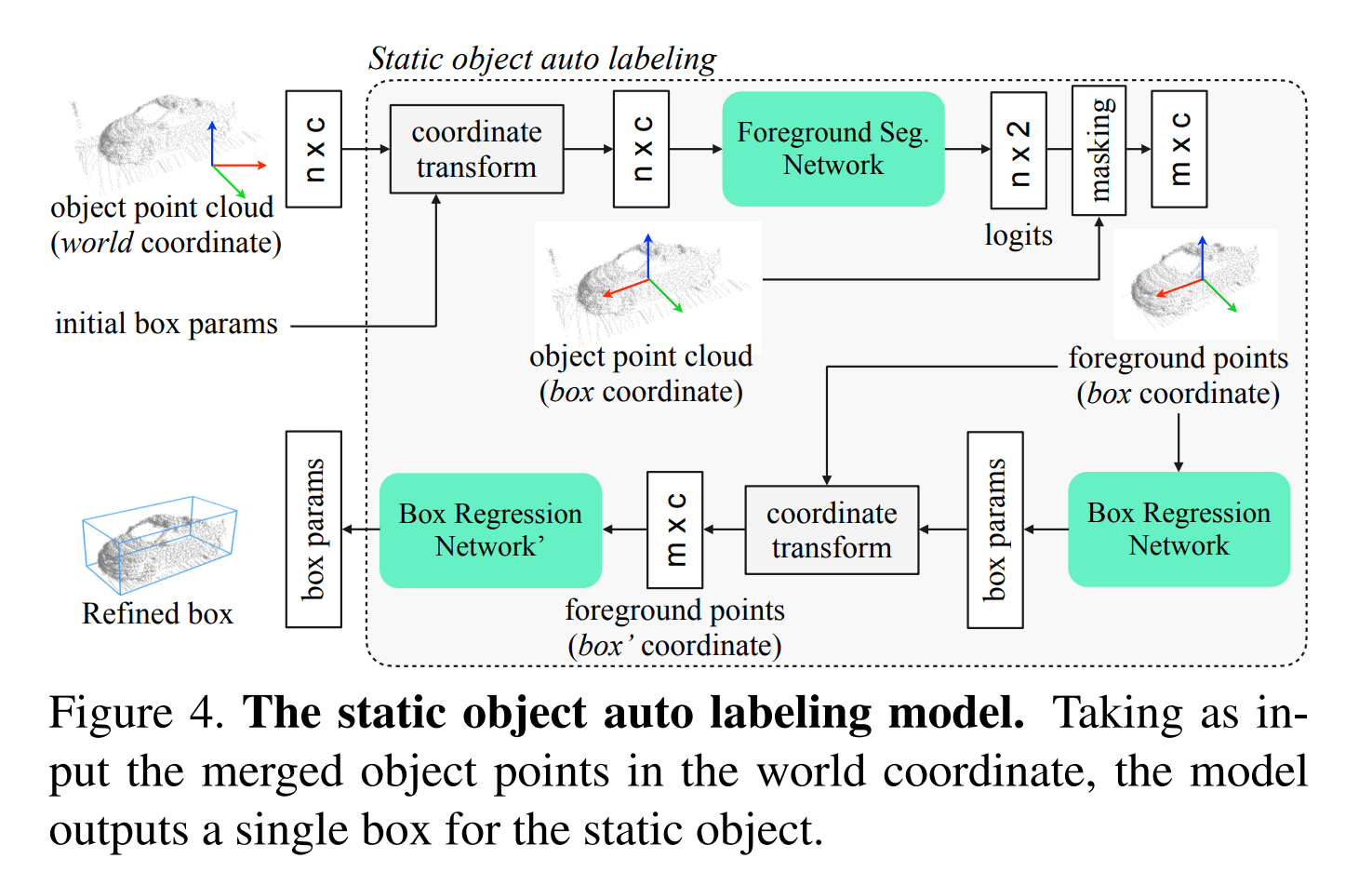
Static Object Auto Labeling
该模块的输入依然是之前融合的点云 merged point clouds,并对每一个物体预测一个选框
论文先将物体中的点云转移到 box coordinate,个人理解是将物体中的点云坐标转移到以物体为原点的坐标系。因为是静态物体,所以多帧的重合度应该挺高的。对于同一个物体,不需要对每一个帧都做这样的坐标转移操作,而是选择一个帧,以该帧的物体作为原点,然后再将所有帧中物体的点转移到该 box coordinate 下。论文中直接选择得分最高的那一个帧作为选择 box coordinate 标准
所有的预测网络都是 PointNet 结构(看来 PointNet 作为二阶段可能会成为一个主流,Lidar R-CNN),为了进一步提高表现,还是用了 segmentation 辅助任务以及 Cascade RCNN 级联检测。整体的流程示意图如下
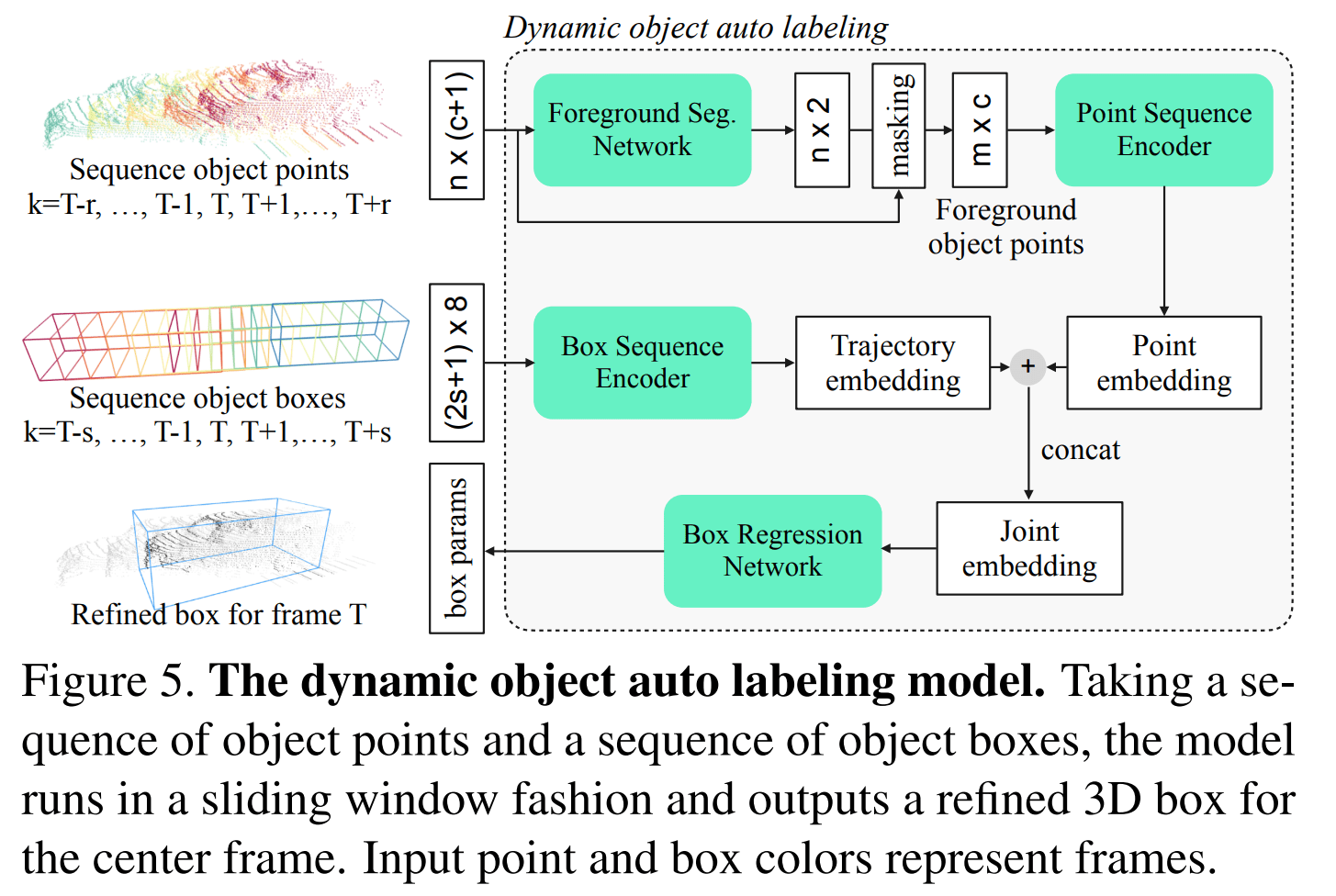
Dynamic Object Auto Labeling
对于动态物体,论文对每一个帧都去预测选框(这样做不会造成抖动吗?)
对于某个动态物体比较难将多帧信息转移到同一个 box 中做融合,因为其中的运动(车辆)和变换(行人)都不太好操作,所以论文选择对序列采取操作。序列是以滑动窗口形式呈现,对于关键帧 k(也是当前帧),使用其上下文 2r or 2s 个帧去预测关键帧中的物体选框
论文也是使用了2个 branch 去处理:
- Point cloud branch,该分支使用一个目标的点云子序列 $\set {P_{j,k}}_{k=T-r}^{T+r}$,将时间戳信息添加到其中,然后将所有的点转移到关键帧 box coordinate $B_{j,T}$,之后使用一个分割网络获得更精细的前景点,再对每个物体使用另一个网络对该点云序列进行编码,得到 point embedding
- Box sequence branch,该分支使用一个目标的选框子序列 $\set {B_{j,k}}_{k=T-s}^{T+s}$(该序列相比于 point branch 可以取更长),依然是先加入时间编码,然后选框转移到关键帧的选框坐标系中,此时 box 表示为8维向量(7维空间 + 1维时间),最后使用一个 PointNet 对该选框序列进行编码,得到 trajectory embedding
- 得到 point embedding & trajetory embedding 之后,将二者 concat 连接,然后输入回归网络,得到最终 box 选框
整体的流程图如下
Experiment
简单整理一下实验结果,只能说效果爆炸
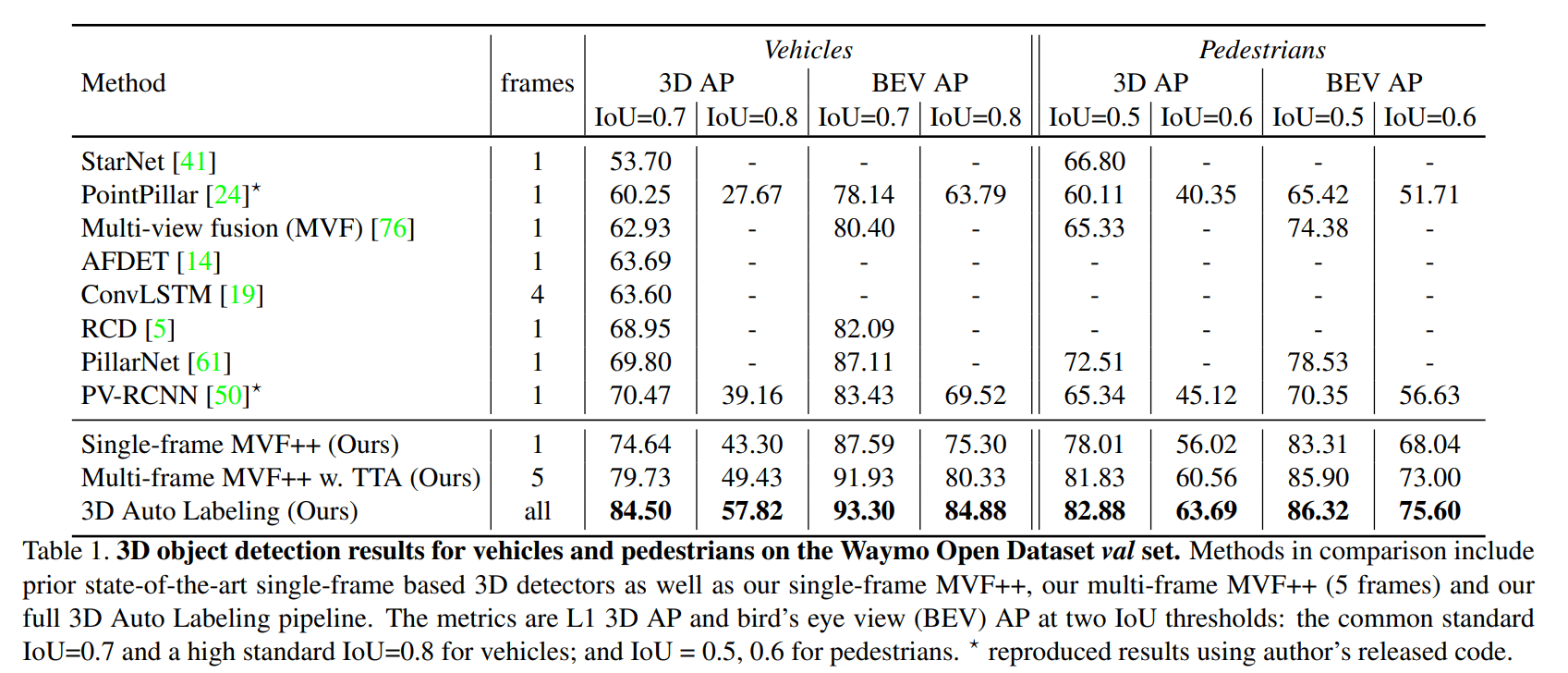
并且能跟人类标注效果比一比

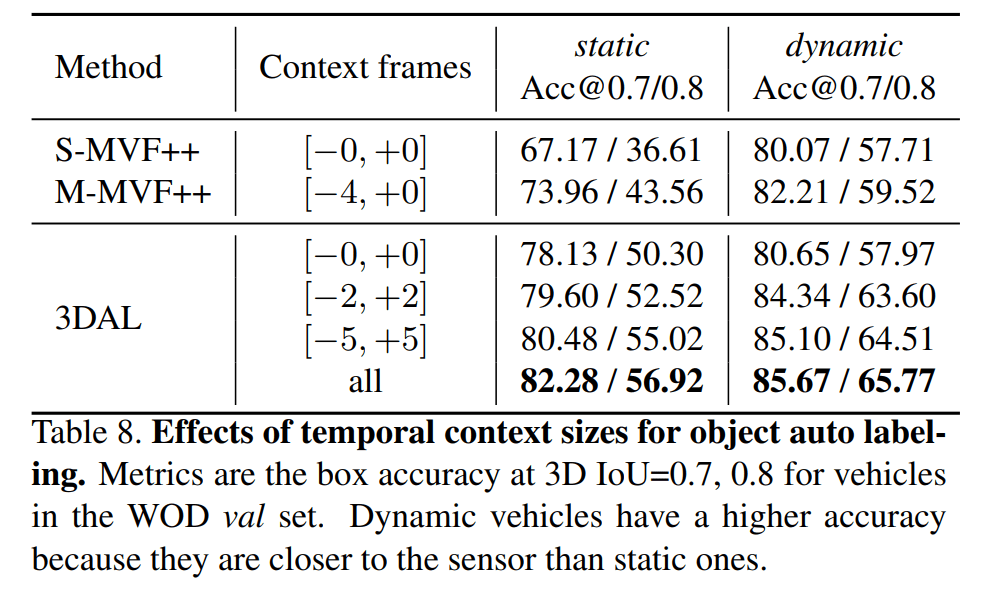
(左侧)将其用于半监督学习效果也很不错,(右侧)MVF++ 的一些消融实验,帧数带来的涨幅边际递减

上下文信息对检测器的影响