Mean Teacher & MoCo
Tarvainen, Antti, and Harri Valpola. “Mean Teachers Are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results.” ArXiv:1703.01780 [Cs, Stat], Apr. 2018. arXiv.org, http://arxiv.org/abs/1703.01780.
He, Kaiming, et al. “Momentum Contrast for Unsupervised Visual Representation Learning.” ArXiv:1911.05722 [Cs], 3, Mar. 2020. arXiv.org, http://arxiv.org/abs/1911.05722.
因为最近的毕设研究有用到 mean teacher 这种半监督方法,再结合到之前看到的 MoCo 这种对比学习的方法,感觉二者有一些相似之处。这里做简单整理
Mean teacher 可以用以下步骤概括,github:
- Take a supervised architecture and make a copy of it. Let’s call the original model the student and the new one the teacher.
- At each training step, use the same minibatch as inputs to both the student and the teacher but add random augmentation or noise to the inputs separately.
- Add an additional consistency cost between the student and teacher outputs (after softmax).
- Let the optimizer update the student weights normally.
- Let the teacher weights be an exponential moving average (EMA) of the student weights. That is, after each training step, update the teacher weights a little bit toward the student weights.
其中第 2,3,5 步是 mean teacher 的核心步骤
Mean Teacher Motivations
半监督训练可以使用一些无标签的数据提升网络效果。其中一个半监督的出发点为:一个好的模型应该对于相似数据应该给出一致的输出。从下面这个图示可以直观了解,为什么半监督 & noise & ensenble 能够让模型变得更好
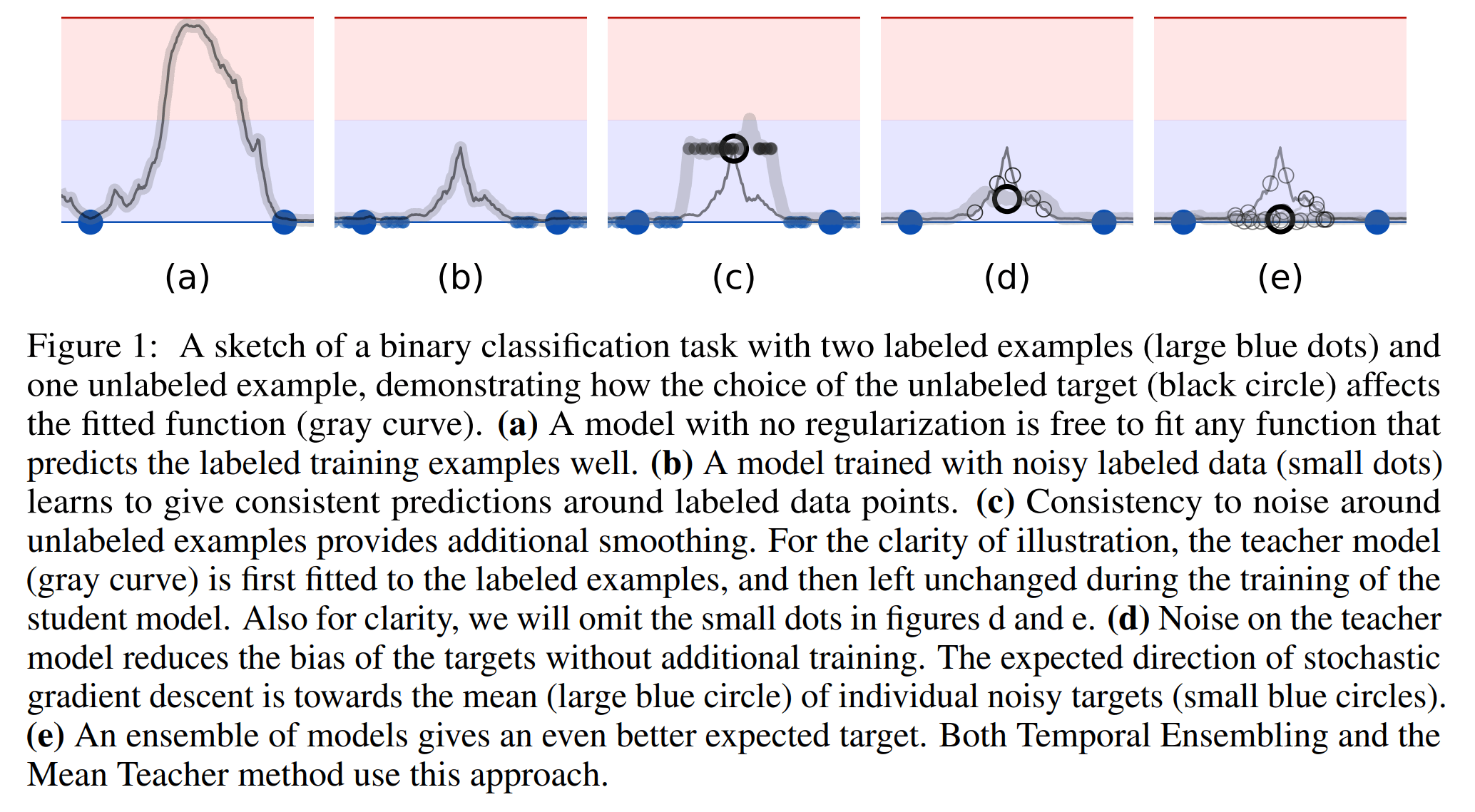
(a) 表示了监督学习可能得到的模型预测结果,这可以看作是一个 overfitting 的结果
(b) 表示了使用 noisy labeled data 后(consistency between noisy data),过拟合被减缓
(c) 表示使用了 unlabeled data with consistency 后,半监督学习将让模型的预测结果更加平滑
(d) 表示对 unlabeled data 得到的预测结果加入 noise,能够进一步减少偏差,让结果更好
(e) 表示进一步使用 ensemle 模型能够更接近于期望目标,达到最好的结果
其实上图就把整个论文的动机描述了个大概。下面再详细提出:
将模型的预测作为标签,并使用这些标签进行”监督“会面临一定的风险,因为这些标签并不一定是准确的。该风险能够被更好的预测结果减缓。基于此提出 noisy teacher/target,具体操作可使用三个方法:
- 对 input 进行数据增强,加入 noise 扰动
- 对预测结果使用 EMA
- 使用更好的模型结构自然也能得到更好的 target
对预测结果进行 EMA 有一个致命缺点:更新频率太慢,对于某一个样本而言,要经过一整个 epoch 才能再次进行 EMA 计算。基于此正式提出 mean teacher,即对 teacher model 进行 EMA,这样能够在每一个 iteration 过后即使进行更新
以上就是 mean teacher 的逻辑,简单好用!
MoCo
参考:MoCo 论文逐段精读
MoCo 是 Momentum Contrast 的缩写,其中 Momentum 可以认为是 EMA 指数平均,Contrast 表示对比学习。对比学习是一种 unsuperviesed/self-supervised learning,MoCo 其实是提出了一种对比学习的范式,把这种范式使用了一个动态字典表示(说是字典,其实存储的数据结构是队列…不过使用了字典中的 key, query 概念),原文描述如下:
We present Momentum Contrast (MoCo) as a way of building large and consistent dictionaries for unsupervised learning with a contrastive loss
上面的两个关键词:large & consistent 就是建造字典的核心。看完这段描述肯定还是云里雾里的,这很正常,下面将里面的概念逐一具体化,然后介绍一下对比学习,最后提出 MoCo 的对比学习流程以及 MoCo 的出发点
Dictionary
这里的字典是指什么?这里的字典是一个队列容器,里面存储的对象是经过编码后的数据集样本,我们称字典里的这些编码好的样本为 key
Contrastive Learning
计算对比损失是无监督训练的一种方式,我们希望相似的物体有着相似的特征,通过设计对比损失函数将不同的特征更好地区分开来。结合上面提到的字典,我们可以很轻松地构造这样的过程:
- 假设我们已经建造好了一个字典,字典里存储着大量的编码好的样本,key
- 获得当前样本,并将其通过编码器,获得当前样本的编码,query
- 计算 query 和所有 key 之间的损失
Contrastive Loss
现在问题就来了,怎么构造损失函数,来满足这样的要求?首先我们需要一种方式,定义 key 和 query 是否是相似的,这样才能进一步计算损失。相似的物体肯定具有相似的特征,但是这不是无监督训练吗,哪来的物体标签呢?这里论文使用了 instance discrimination 的代理任务,它不需要标签来定义相似与否,简单来说:每个样本都与(augmented 后的)自己相似,与其他样本不相似。相似就是正样本,不相似就是负样本
论文直接使用了一个多分类任务来建模这样的学习过程
所有的正负样本独立为一类,其中正样本只有一个 $k_+$(来自于增强后的自己),字典中的全是负样本 $k$(来自于其他样本),现在我们就要计算出 query $q$ 属于哪一类的概率分布,使用 点积 + softmax 来建模是很直接的想法
其中 $\tau$ 是一个超参数。通常可认为设定,i = 0 时,$k_0$ 是唯一的正样本 $k_+$,i = 1,…,K 时,都是负样本。此时 $q$ 根据定义肯定是属于正样本类的,那么交叉熵就可以计算为
MoCo Algorithm
积木都准备得差不多了,就可以开始搭建了。下图是整个 MoCo 算法的示意图,比较简洁
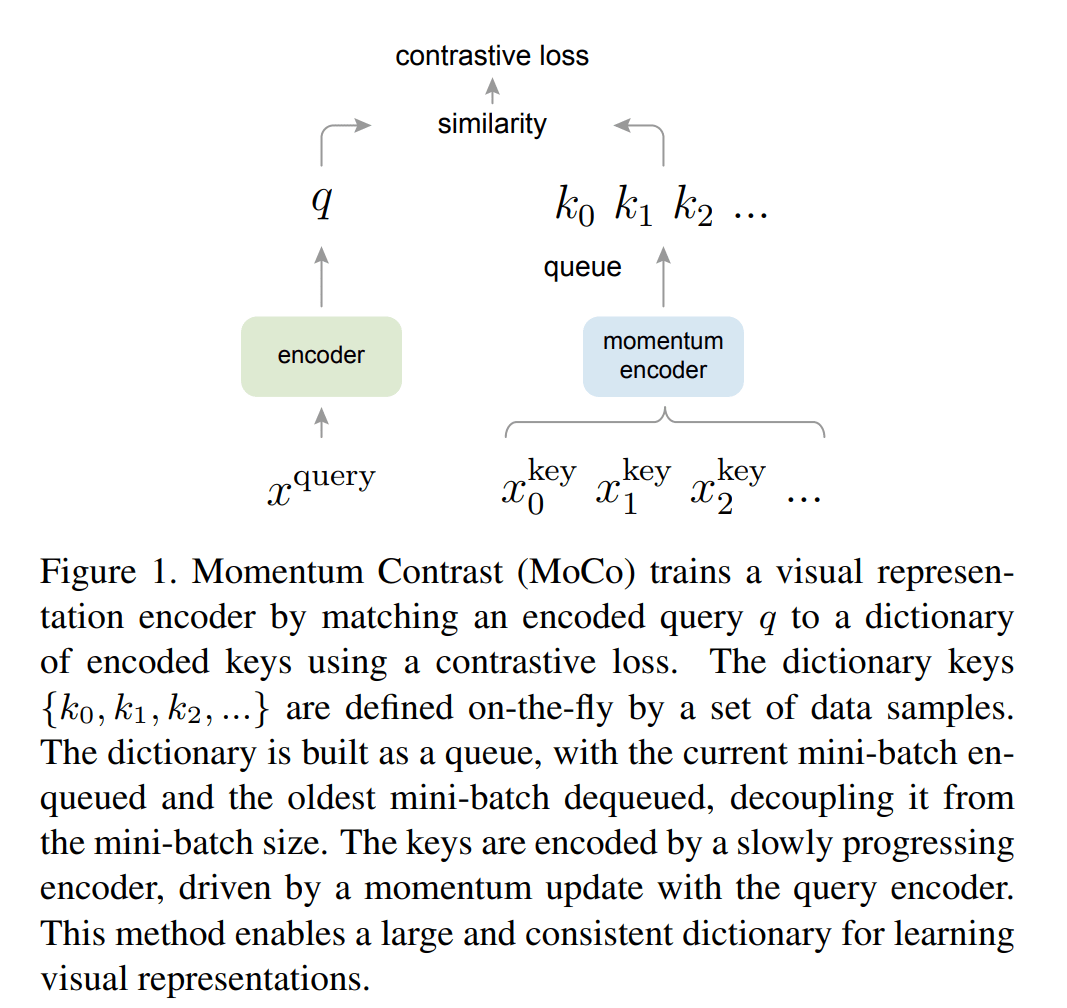
看一下之前留下的坑:我们并没有说怎么去建造字典,也没有说怎么去建造 encoder。只要把这两个问题填上,MoCo 的流程就跃然纸上了
- 怎么去建造字典?论文使用了一个队列去建造。当前样本经过 encoder 编码后得到 $q$,同时当前样本还要通过数据增强经过 momentum encoder 得到 $k_0$,将 $k_0$ 入队,并计算损失,计算完后,队列头部 key 出队
- 怎样去建造 encoder?当前样本经过的 encoder 就是当前的 encoder,对于字典中的 key 经过的是 EMA encoder,即经过指数平均的 encoder
论文直接给出了算法的 pytorch style 伪代码,简直清晰得一批,比看图更清楚!

MoCo Motivation
之前提到了:large & consistent 就是建造字典的核心,最后来填这个坑,了解 MoCo 算法的出发点
- Why large?大字典就以为着更多的样本被保存了下来,这样的好处是不言而喻的,相当于你拥有了更多的信息和参照物
- Why consistent?对比的特征,应当在相同的或者相似的编码器下得到,不然对比是没有意义的。那为什么不直接 copy 当前的编码器,而使用 EMA 得到的编码器?因为在训练的过程中,编码器的更新可能会非常的迅速,这也将会导致编码器的不一致
看到这里是不是发现了这和 mean teacher 有着神似之处?似乎这是 mean teacher 的一个升级,不仅仅看当前样本,还看到了其他样本;不仅仅看到了正样本,还看到了负样本
MoCo v2
v2 里面借鉴了 SimCLR 中的一些简单操作,但是巨有效果。主要有提升的是两个:1. 使用了 MLP/affinity 对 key 进行再次编码,然后再进行损失计算;2. 更好的数据增强
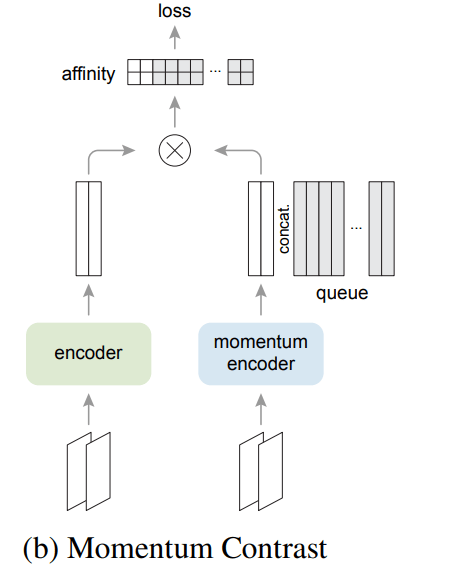
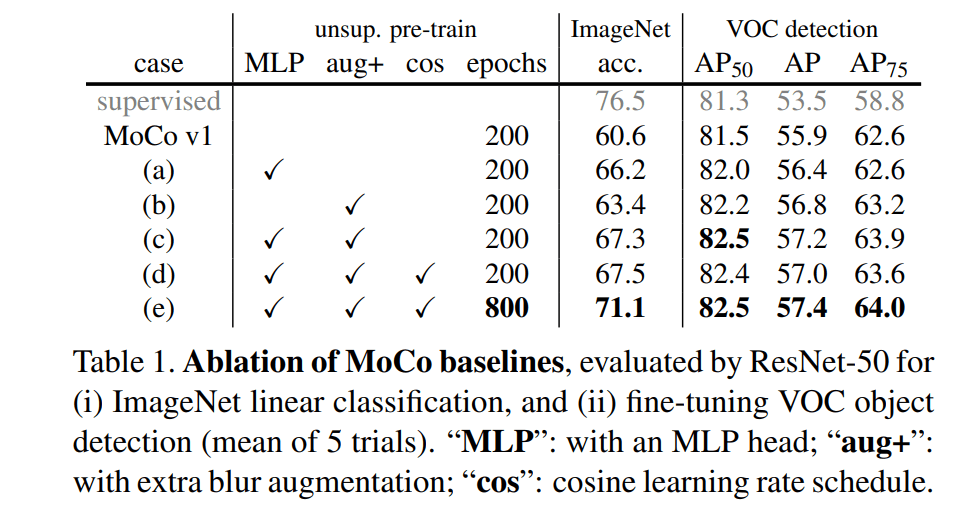
尤其是加了 MLP 过后直接暴涨6个点!
Future
Beyond the simple instance discrimination task [61], it is possible to adopt MoCo for pretext tasks like masked auto-encoding, e.g., in language [12] and in vision [46]. We hope MoCo will be useful with other pretext tasks that involve contrastive learning.
在论文末,作者就已经谈论到了将 MoCo 的 pretext task 换为更好的 masked autoencoding。实际上在一年多过后,Kaiming 大佬就带着 MAE 论文回来了,这似乎又宣布了有监督和无监督之间的差距被进一步缩小


