VoxelNet & SECOND
Zhou, Yin, and Oncel Tuzel. “VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection.” ArXiv:1711.06396 [Cs], November 16, 2017. http://arxiv.org/abs/1711.06396.
Yan, Yan, Yuxing Mao, and Bo Li. “SECOND: Sparsely Embedded Convolutional Detection.” Sensors 18, no. 10 (October 6, 2018): 3337. https://doi.org/10.3390/s18103337.
VoxelNet
Introduction
VoxelNet 作为体素化处理点云的奠基之作,其地位也是相当高的。该论文为之后的体素化框架提供了通用的思路:该网络将点云分割为均匀的 3D 体素块,并将每一个体素内的点使用统一的特征表示。然后再将 3D 特征图谱转化为 BEV 特征图谱进行选框预测
在当时对于点云特征提取还处于起步阶段,PointNet 刚刚问世,对于特征提取不再使用人工设计特征,多视角融合的方法也逐渐被超越。但是 PointNet 庞大的运算量是一个亟需解决的问题,为了有效地利用点云,将其进行体素化表示不失为一个好方向,规则化的数据结构一般是更利于存储与学习的,VoxelNet 应运而生
VoxelNet Architecture
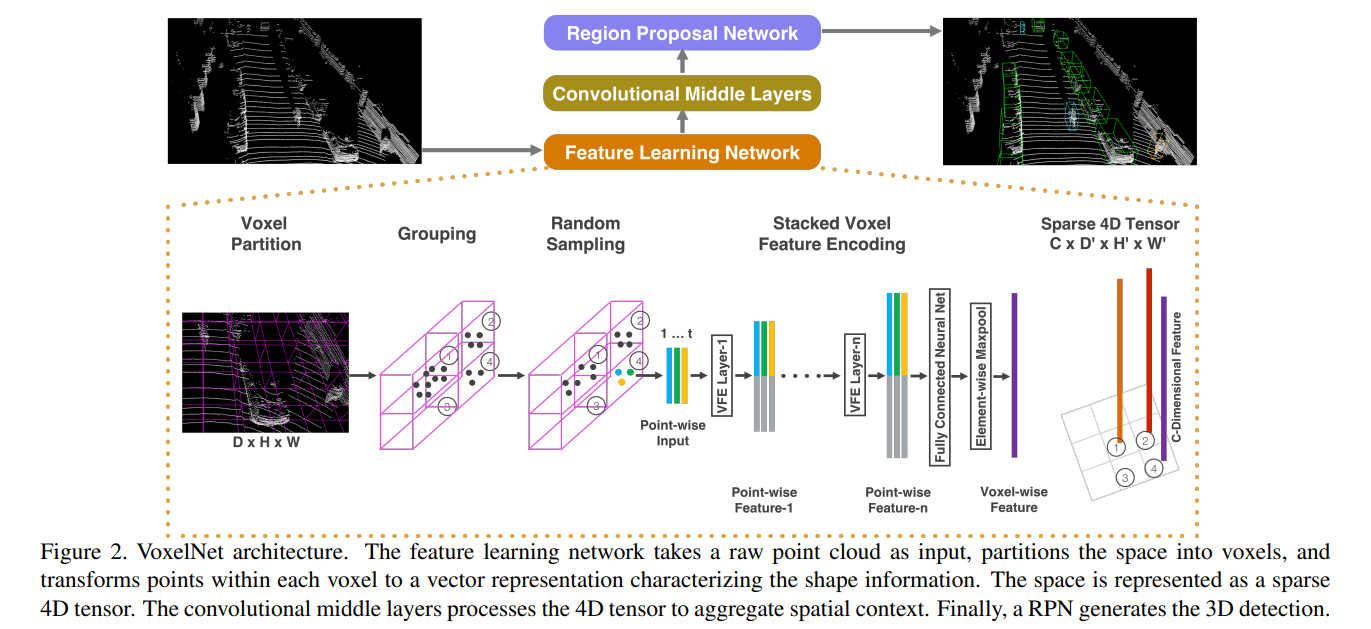
Feature Learning Network
这一部分是整个网络的核心,详细地描述了如何将点云编码为体素化特征图谱。首先是将网络分割为均匀的体素块,最终可以使用 $(D,H,W)$ 形状的矩阵来表示该体素化点云。由于点云中能够包含 ~100k 数量级的点,所以对每个体素块 $(d,h,w)$ 中的点的数量进行限制,最多不超过 $T$ 个点,这样的限制能够很好的节约计算,平衡每个体素块内的点云数量
接下来就是使用多个体素特征编码模块 voxel feature encoding (VFE) 对每个体素块内的点云进行特征提取,下面对 VFE 模块进行详细了解。其中一个非空体素块特征表示为如下公式
即该体素块中所有的点,其中 $r_i$ 为反射强度。将该特征进行增强,加入每个点距离该体素中心的偏移量
将该特征送入网络(FCN + BN + ReLU)得到每一个点的特征 $\mathbf{f}_i \in \mathbb{R}^m$,然后再使用 MaxPooling 获得该体素的整体特征 $\tilde{\mathbf{f}}_i \in \mathbb{R}^m$ 。(其实这个结构与 PointNet 是相似的,只不过论文中名称叫 FCN/MLP 而不是 shared MLP,但实际上 FCN 的权重是所有非空体素共享的)
将体素的特征与逐点的特征 point-wise feature 连接起来
该操作是为了给每个点增加其所在体素的信息。以上就是第一个 VFE 模块的操作过程,将体素中的点云编码为统一形状的特征向量,图示如下
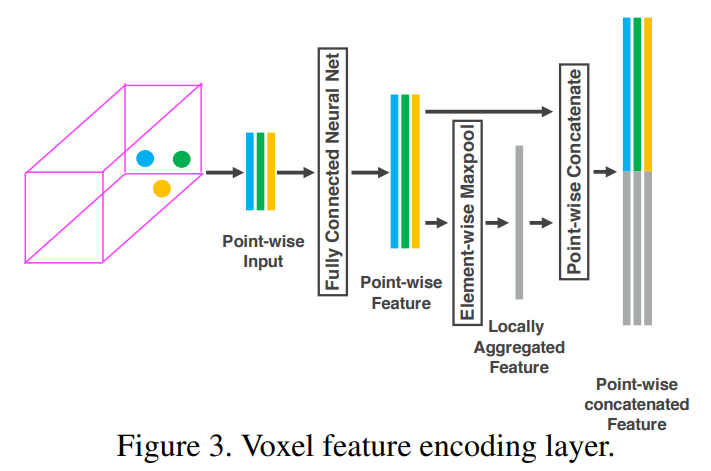
论文使用多个这样的 VFE 模块,不断地对点云进行特征提取操作,最后一个 VFE 模块在使用 MaxPooling 后,不再将其连接到逐点的特征上,即最终得到了一个逐体素的特征图谱 voxel-wise feature,每个体素的特征维数记为 $C$,整个点云的特征图谱表示为 $(C, D, H, W)$ 形状的矩阵
Convolutional middle layers
这部分论文以少量的文字描述略过。就是对提取出来的体素特征进行卷积操作,表示为 Conv3D(C_in, C_out, kernel_size, stride, padding)。这一结构的逐渐聚集体素特征,缩小特征图谱分辨率,不断提升图谱中每个像素的感受野
Region Proposal Network
首先将 3D 的特征图谱沿着 z 轴,重塑 reshape 为 2D 的 BEV 俯视特征图谱。转换到二维过后就是熟悉的领域了,先使用多个二维卷积模块 Conv2D 进行特征提取,然后将不同分辨率的特征图谱进行上采样或者叫反卷积 upsampling/deconvolution。经过上采样后,得到多个分辨率相同的特征图谱,然后将它们连接起来,使用 anchor-based detector 进行分类任务和回归任务。整个 RPN 网络的结构如下图所示
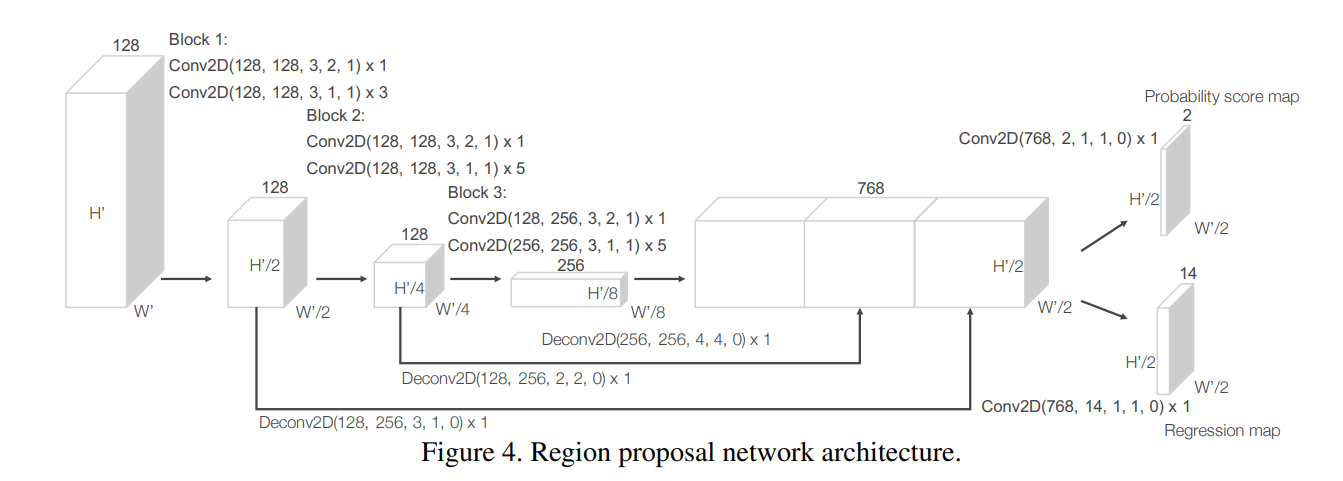
对于 anchor 的设置不像二维一样有很多个尺度的 anchor,论文仅使用了一个 anchor size 和两个旋转角度(水平和垂直)作为预定义选框
Loss function
关于回归任务使用的是对数大小 logarithmic size 的残差值作为拟合对象/标签,而不是直接使用真实的残差值,具体这么做的原因我不太清楚,可能对数函数能够让标签更加平滑,并且从图像上来看,log 函数能够稍微降低惩罚
回归任务的损失函数为 smooth L1 loss,分类任务使用交叉熵损失 cross entropy loss(这个时候 focal loss 还没诞生,在之后其升级框架 SECOND 中使用了)
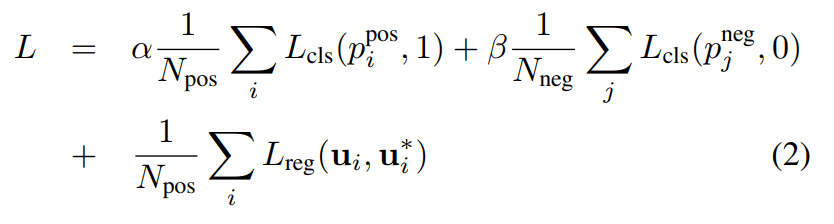
由于是 anchor-based RPN 依然是要对预定义选框 pre-defined anchors 进行正负分类的,而且回归损失对 positive anchor 所预测的选框计算损失
Data structure
既然使用了体素化表示,必定带来数据结构上的表示优势。由于点云的稀疏性,有大量的体素内部是没有点云的,此时使用哈希表能够快速地查找体素阵中的非空体素。假设非空的体素块最多有 $K$ 个,初始化一个 $(K,T,7)$ 形状的矩阵以存储每个体素及其内部点云的特征,其中 $T$ 代表一个体素内最多有 $T$ 个点,$7$ 代表原始点云的特征。以每个体素的坐标作为 hash key 制作 hash table,通过遍历所有的点,就能够将每个点分配到对应体素中,最终给出体素的坐标,就能够迅速查找出该体素内所有采样点的信息。以上构造哈希表+特征提取的过程可以用下图表示
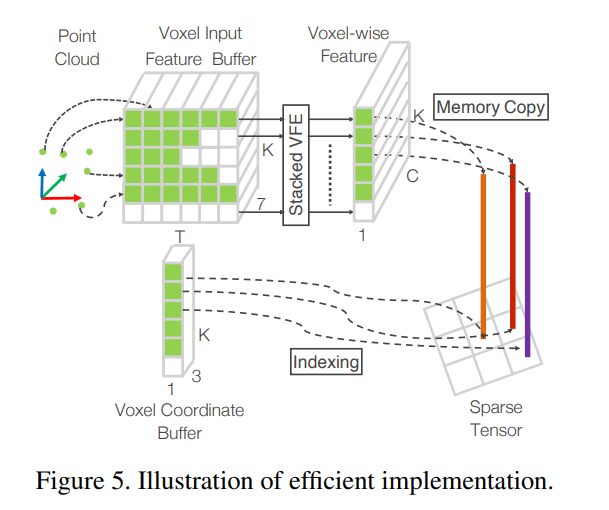
SECOND
SECOND 可以说就是 VoxelNet 的升级版本,更快更准,其整个 SSD 检测框架可以说已经成为 Voxel-based SSD 的主流,是现在经常使用的 backbone 之一,能够非常有效地将点云体素化并进行三维卷积操作。这一部分仅介绍一下 SECOND 网络为什么更快,这也是该论文的重点贡献之一,使用了稀疏卷积/子流形卷积 sparse convolution/submanifold convolution 改进了原来的三维卷积操作,省去了大量对空体素的卷积操作(点云的稀疏性导致大量体素块为空),从而加速计算。下面留两个参考链接,
其核心思想也是和 hash table 类似,创建一个 RuleBook 记录下每个体素块的输入位置在哪里、输出位置在哪里、对应相乘的卷积核权重在哪里。通过遍历这个 RuleBook 即可完成三维卷积操作
下面仅留一张示意图以便快速复习(如果没看过参考链接应该是很难看懂)
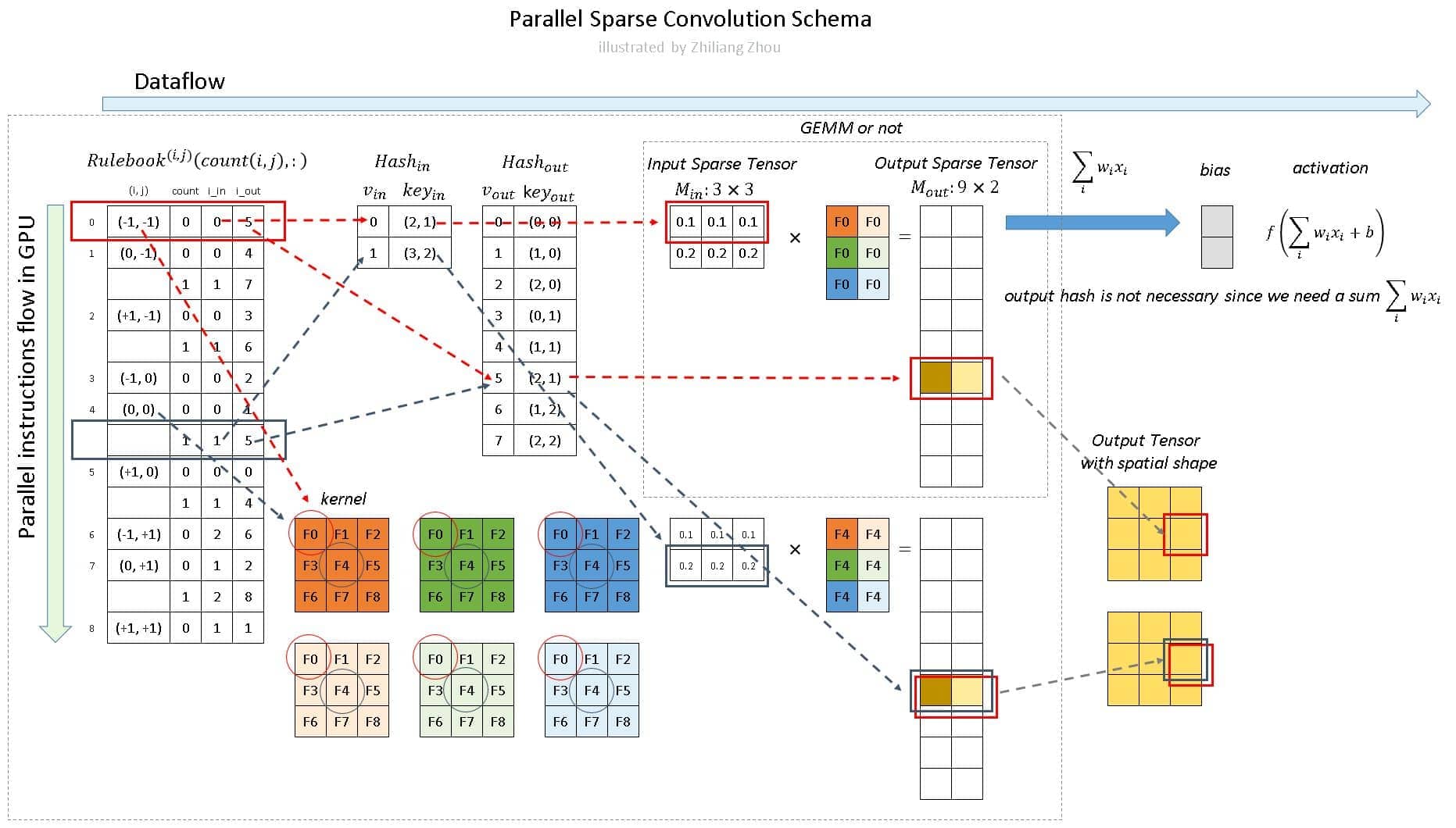
个人再重新总结一下:
- 构建稀疏向量 sparse tensor
- 通过稀疏向量构建 RuleBook (hash in table & hash out table 包括其中),从逻辑上理解:该 RuleBook 记录了输入的稀疏向量位置和对应卷积核位置 $(i, j)$ 以及其输出稀疏向量的位置,但实际上是以卷积核位置 $(i, j)$ 为主导建立的
- 同时并行计算所有的输入稀疏向量,并获得输出稀疏向量
为什么要引入子流形卷积?因为普通的稀疏卷积会让感受野迅速增加,许多 inactive 的点经过卷积过后变得 active,而子流形卷积则保证了 active 点的个数不变,参考 github

除了稀疏卷积的内容之外,SECOND 还贡献有两个重要贡献:
对于方向损失函数的改进
使用正弦 L1 loss 再加上方向二元分类损失,以达到精确的方向定位
对于数据增强的改进
- 从标签池中随机采样 Sample Ground Truths from the Database
- 对每个标签随机旋转 Object Noise
- 对整个点云随机旋转和随机缩放 Global Rotation and Scaling
Experiment
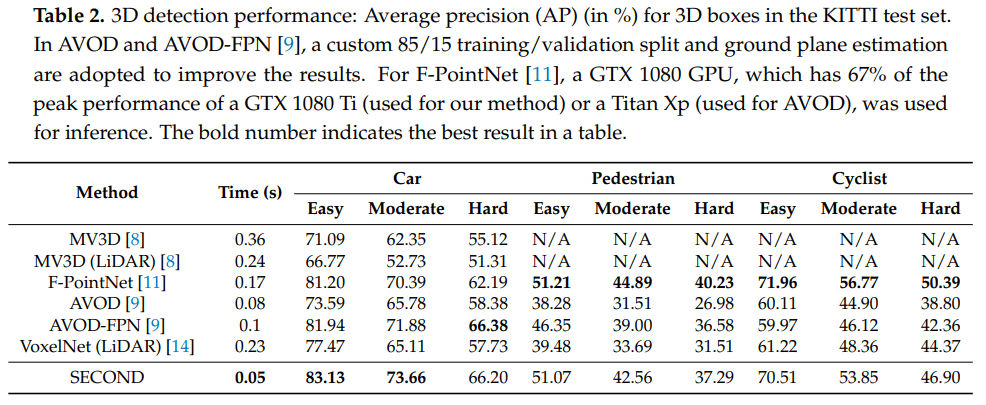
SECOND 在速度上相比于 VoxelNet 提升了接近5倍,已经能够达到实时检测的标准(20+ fps),这在速度上是完全的碾压,而且在准确率上也远远领先
Conclusion
以上则是对 VoxelNet 和 SECOND 的总结,这两篇已经是好几年前的文章了,也是三维点云体素化方向的奠基之作。在很多论文中都将到了这两篇的身影,所以了解一下其中的实现细节,能够帮助更好地理解其他论文的结构


