D2L 14 自然语言处理:预训练
Word2vec
词向量是用于表示单词意义的向量, 并且还可以被认为是单词的特征向量或表示。 将单词映射到实向量的技术称为词嵌入。 近年来,词嵌入逐渐成为自然语言处理的基础知识。虽然独热向量很容易构建,但它们通常不是一个好的选择。一个主要原因是独热向量不能准确表达不同词之间的相似度,比如我们经常使用的“余弦相似度”
word2vec 工具是为了解决上述问题而提出的。它将每个词映射到一个固定长度的向量,这些向量能更好地表达不同词之间的相似性和类比关系。word2vec 工具包含两个模型,即跳元模型(skip-gram)连续词袋(CBOW)
跳元模型(skip-gram)
跳元模型假设一个词可以用来在文本序列中生成其周围的单词。以文本序列“the”、“man”、“loves”、“his”、“son”为例。假设中心词选择“loves”,并将上下文窗口设置为2,假设上下文词是在给定中心词的情况下独立生成的,联合条件概率可用如下图表示
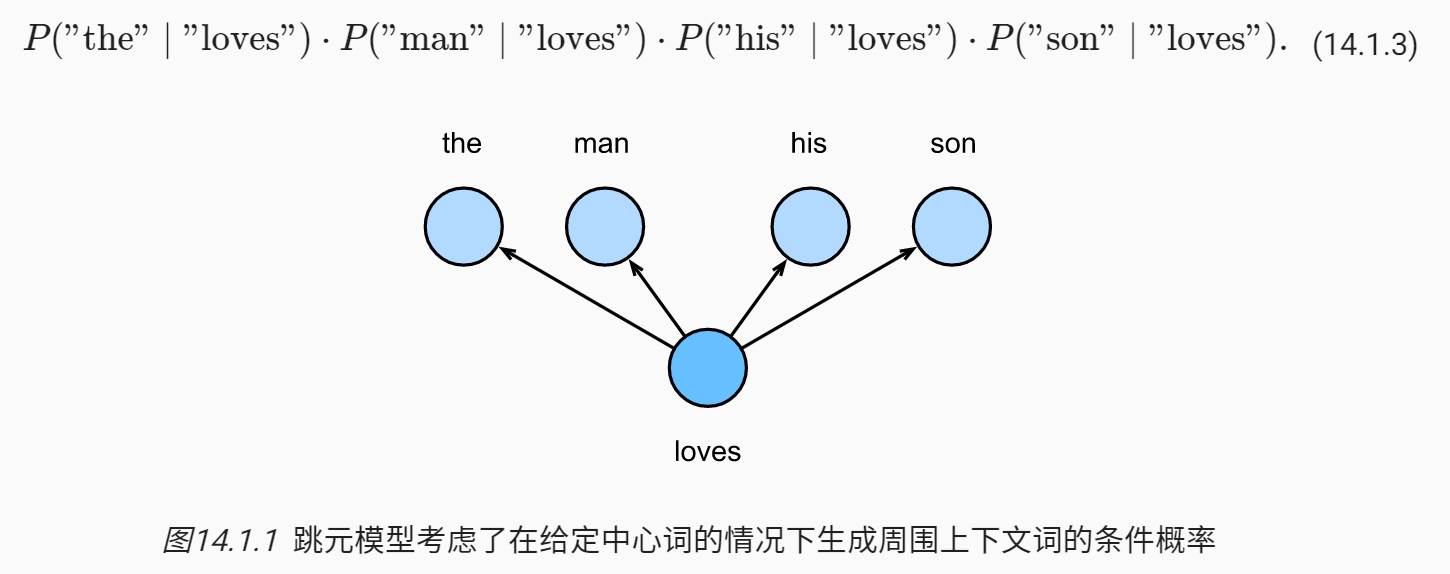
在跳元模型中,每个词都有两个 d 维向量表示,用于计算条件概率。给定中心词 $w_c$(词典中的索引 c),生成任何上下文词 $w_o$(词典中的索引 o)的条件概率可以通过对向量点积的 softmax 操作来建模
其中词表索引集 $V={0,1,…,|V|−1}$。给定长度为 $T$ 的文本序列,其中时间步 t 处的词表示为 $w^{(t)}$。假设上下文词是在给定任何中心词的情况下独立生成的。对于上下文窗口 m,跳元模型的似然函数是在给定任何中心词的情况下生成所有上下文词的概率:
做深度学习久了,感觉所有东西必须要有一个标签才能计算损失函数,然后使用梯度下降算法进行优化,看到这里还有点不太习惯😂实际上该似然函数就是我们的目标函数,我们可以通过优化神经网络的参数获得似然函数的最优解
连续词袋(CBOW)模型
连续词袋类似于完形填空,给定上下文推理出空缺词。
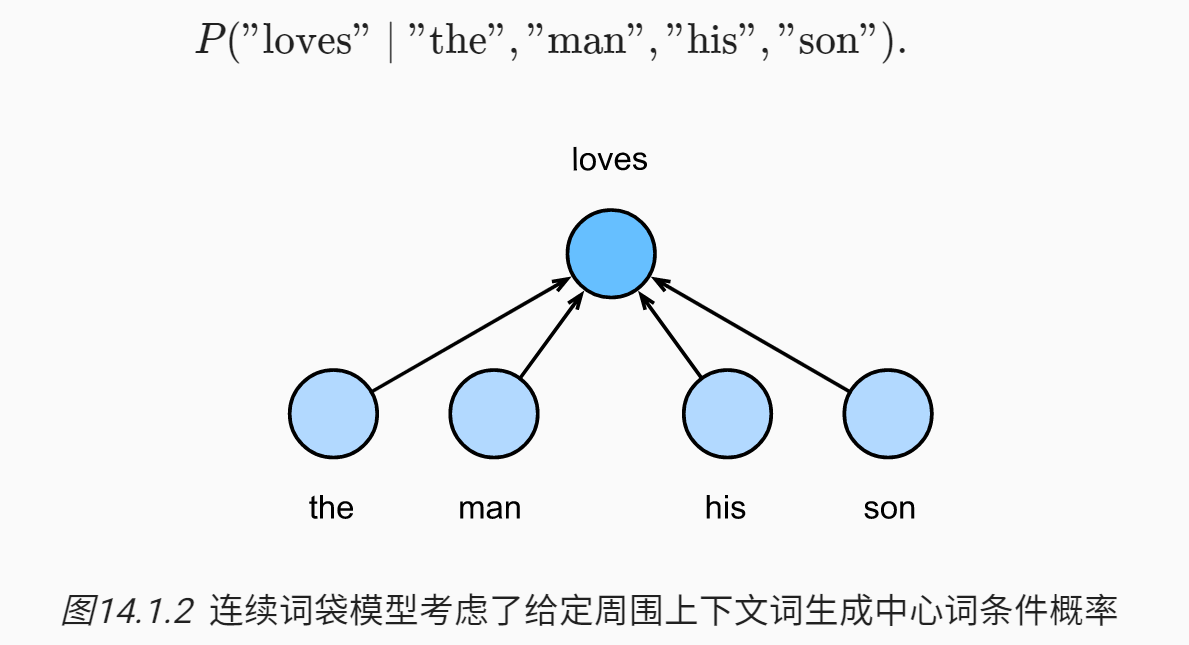
由于连续词袋模型中存在多个上下文词,因此在计算条件概率时对这些上下文词向量进行平均,假设有 2m 个上下文词
连续词袋模型的似然函数是在给定其上下文词的情况下生成所有中心词的概率
近似训练
可以看一看 官方视频,比教材还要讲得更清楚。由于跳元模型和连续词袋模型非常相像,之后都以跳元模型进行说明
如果我们对跳元模型的目标函数进行求导可得:
可以发现其中有一个求和项,对于词典数量 V 很大的情况,计算量会非常大,为了解决这个问题提出了两个方法
负采样
上面的求和问题是由于 softmax 的计算方式导致。直接采用 sigmoid 进行概率表示就不会有这样的问题,我们现在来建模另一个概率事件
其中出现了一个新的随机变量 D,该变量表示 $w_c, w_o$ 是否出现在同一个上下文窗口,如果在则 D = 1 如果不在则 D = 0。也就是说,我们用两个词是否出现在同一个窗口来进行建模。但采用这样的建模方式是有问题的,因为当你去最大化似然时,得到的所有词向量将会是一个无穷大的数。为了让模型变得合理,我们加入负样本/噪声样本/背景样本,负样本通过人为设定的先验概率 P(w) 采样得到。我们采样 K 个负样本 $w_k$,并重新写出概率
此时我们将原始的模型分解为了两部分:两个词在同一窗口内,两个词不在同一窗口内。此时该模型将不再含有 softmax 当中的求和,计算量由采样数 K 限制。将目标函数写得具体一些
层序 Softmax
这个东西不太好理解,我也不太想要深究,贴一下图和公式
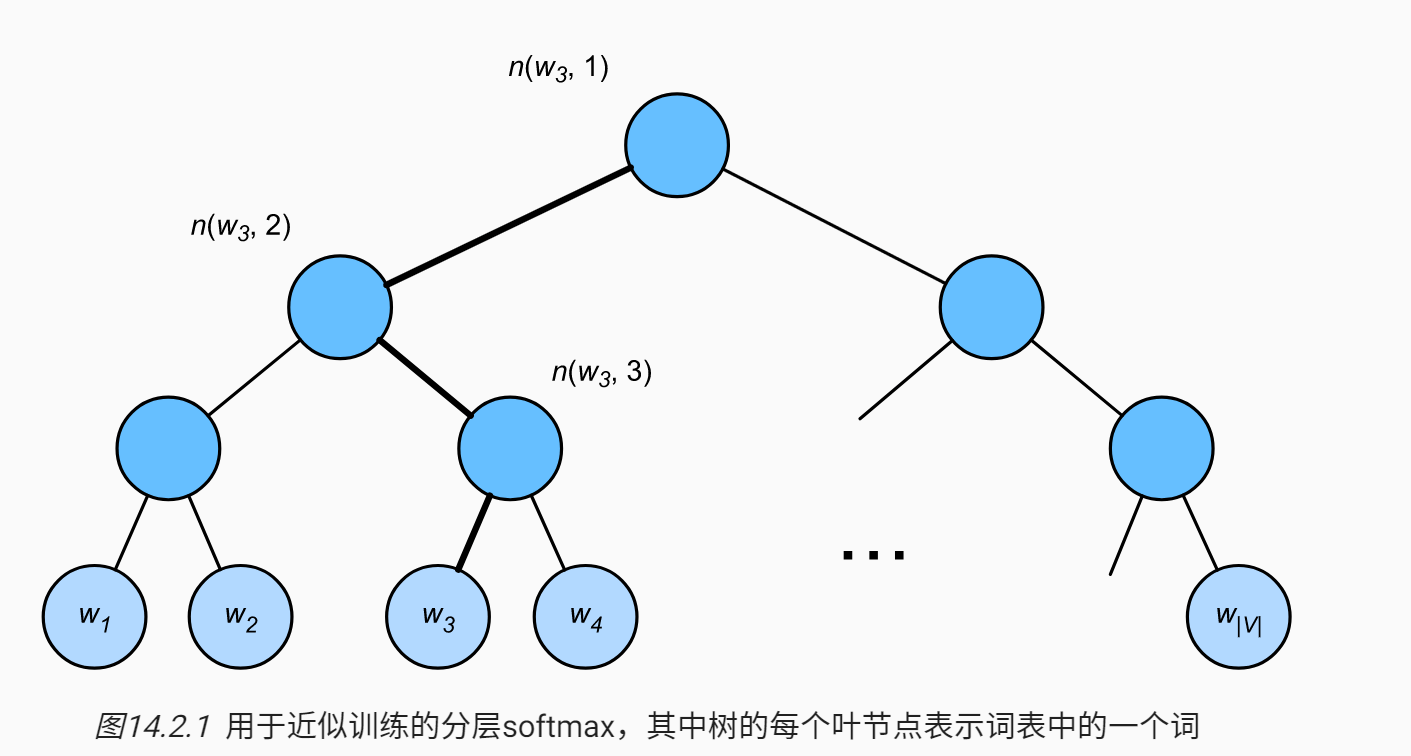
依然还是使用 sigmoid 去建模概率,但是编码是采用了一个二分的编码方式,不明白这样编码的有效性
预训练 word2vec
只记录负采样的跳元模型
嵌入层
嵌入层将词元的索引映射到其特征向量。该层的权重是一个矩阵,其行数等于字典大小(input_dim),列数等于每个标记的向量维数(output_dim)。在词嵌入模型训练之后,这个权重就是我们所需要的,nn.Embedding
embed = nn.Embedding(num_embeddings=20, embedding_dim=4)前向传播
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):
v = embed_v(center) # (B, 1, H)
u = embed_u(contexts_and_negatives) # (B, M, H)
pred = torch.bmm(v, u.permute(0, 2, 1)) # (B, 1, M)
return pred看代码就非常清晰,首先有两个 embedding 层分别对应 center embedding 和 context embedding(是的,二者是不同的 embedding,我之前认为一个词只有一个 embedding),然后使用批量矩阵乘法获得最后的结果
损失函数
这里使用的是 masked binary cross entropy loss
class SigmoidBCELoss(nn.Module):
# 带掩码的二元交叉熵损失
def __init__(self):
super().__init__()
def forward(self, inputs, target, mask=None):
out = nn.functional.binary_cross_entropy_with_logits(
inputs, target, weight=mask, reduction="none")
return out.mean(dim=1)
loss = SigmoidBCELoss()要理解这个损失函数,要回答两个问题:1. 为什么要带掩码?2. 损失函数的输入和标签是什么?
第一个问题很好回答,因为上下文的长度是不一样的,需要 mask 掉 padding 的部分不计算损失。第二个问题先给答案:输入为前向传播的预测结果 pred (B, 1, M),输出是正负样本标签 (B, 1, M) 代表这个词是否在上下文窗口中
这样的标签是非常合理的,但是在之前的笔记中提到:最大化似然函数不需要标签,为什么不用之前的 MLE 去做最优化呢?因为在分类问题上二者是等价的,知乎
GloVe
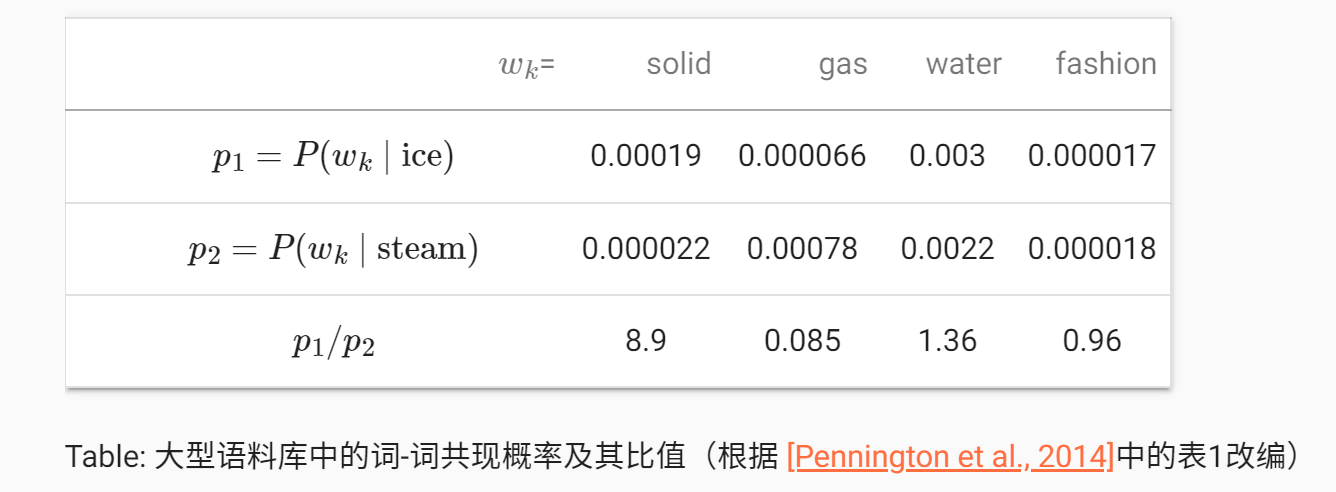
没能理解,不打算深入学习。似乎这种方法是想要建模一个三词之间的条件关系,该建模建立在一个共现矩阵上(词 j 出现在词 i 上下文的频率),共现概率的比值能够直观地表达词与词之间的关系
FastText 子词嵌入
fastText 在使用负采样的 skip-gram 模型基础上,将每个中心词视为子词 subword 的集合,并学习子词的词向量,用子词词向量的和来替代原来中心词词向量
让我们来说明如何以单词 “where” 为例获得 fastText 中每个中心词的子词。首先,在词的开头和末尾添加特殊字符“<”和“>”,以将前缀和后缀与其他子词区分开来。 然后,从词中提取字符 n-gram。 例如,值 n=3 时,我们将获得长度为3的所有子词:“
假设 $z_g$ 是词典中的子词 g 的向量,则跳元模型中中心词向量 $v_c$ 我们计算为其子词向量的和:
于是 fastText 模型可以表示为:
从上面两式可以很清楚地看到改动的区别。这样改动的意义在哪里呢?教材简单总结:子词嵌入可以提高稀有词和词典外词的表示质量。可能因为它对词的单词内部也进行了一定的建模吧,这样做的出发点也是由于某些语言特性导致,因为一个单词往往可以拆解为多个词根
词的相似性和类比任务
本来想跳过这一节的,还是把教材里的小结贴一下吧,有个概念:
- 在实践中,在大型语料库上预先练的词向量可以应用于下游的自然语言处理任务
- 预训练的词向量可以应用于词的相似性和类比任务
BERT
终于来到自己最想要了解的部分了😎主要参考官方视频 bilibili,因为想更好的了解模型的内在逻辑
NLP 里的迁移学习
word2vec 模型的缺点:忽略了部分时序信息,是一种静态的表征。举一个简单的例子:如水果中的“苹果”和苹果公司的“苹果”,在 word2vec 模型中词向量表示是一样的,而实际上这两词的意思完全不一样
BERT 的动机之一:希望通过微调来做下游任务。换句话说,我们希望有一个预训练好的(大)模型,该模型能提取出足够好的嵌入特征,然后直接拿这些特征通过一个简单的解码器(MLP)完成下游任务(当然还有微调的过程)
BERT 架构
简单概括:只有编码器的 transformer
BERT 论文使用了两个版本,下面是一些参数细节:
- Base: # blocks = 12, hidden size = 768, # heads = 12, # parameters = 110M
- Large: # blocks = 12, hidden size = 1024, # heads = 16. # parameters = 340M
BERT 输入
- 每个样本是一个句子对
- 加入额外的片段嵌入。代表是第一个句子,还是第二个句子
- 位置编码可学习
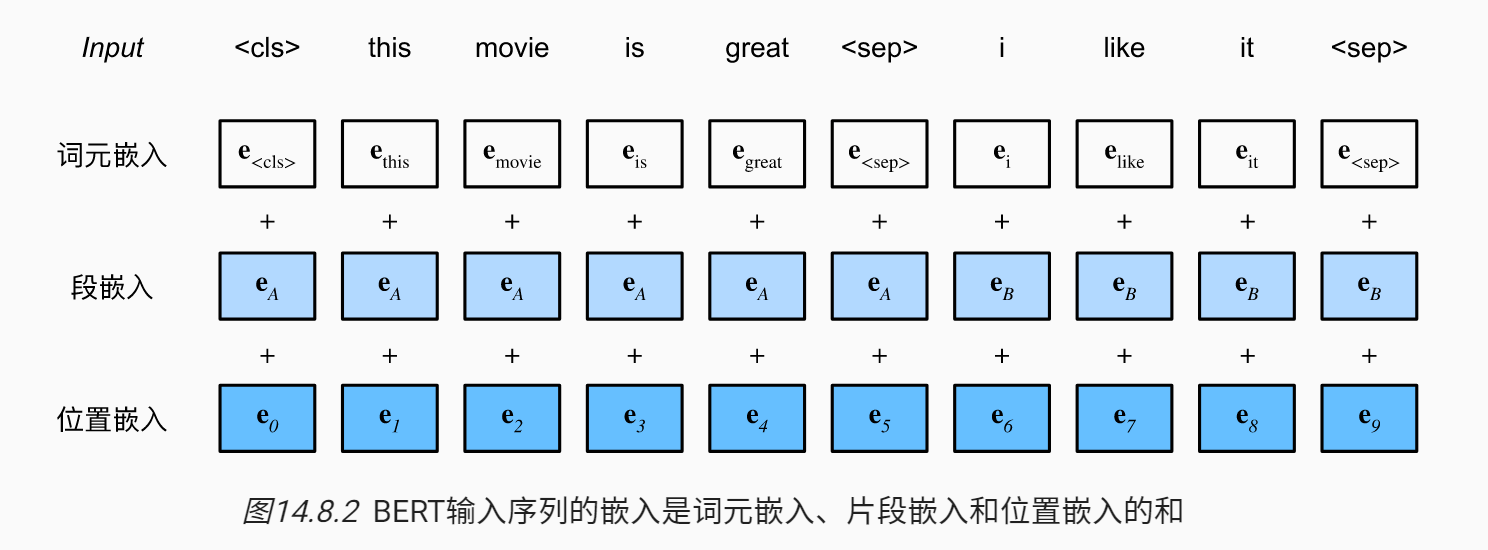
上代码!清晰得一批
#@save
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments上面这段代码是先处理的文本:1. 加入特殊词元(不包含
之后直接使用 nn.Embedding,将输入嵌入到相同的维度上
#@save
class BERTEncoder(nn.Module):
"""BERT编码器"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{i}", d2l.EncoderBlock( # transformer block
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
# 并且不需要 batch 维度, 因为每个 sample 的位置信息编码都应该一样
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return XBERT 预训练任务
带掩码的语言模型
带掩码的语言模型每次随机(15%概率)将一些词元换成
- 80% 概率下,保持
token - 10% 概率下,随机换成其他 token
- 10% 概率下,保持原有 token
下一句子预测
预测一个句子对中两个句子是不是相邻的。在训练样本中:50% 概率先择相邻句子对,50% 概率选择随机句子对。并将
补充:
- 不必过于纠结 BERT 中的 B -> bidirectional,这其实是 transformer 自带的属性,直白的来讲这个 bidirectional 更像是指代一种全局能力
- 沐神提到,他们将 BERT 的代码分为了:数据,模型,训练三部分。这个范式应该要牢记!


