IA-SSD
Zhang, Yifan, Qingyong Hu, Guoquan Xu, Yanxin Ma, Jianwei Wan, and Yulan Guo. “Not All Points Are Equal: Learning Highly Efficient Point-Based Detectors for 3D LiDAR Point Clouds.” ArXiv:2203.11139 [Cs], March 21, 2022. http://arxiv.org/abs/2203.11139.
好久没有看新的文章了…来看看新鲜出炉的 CVPR 2022 的论文吧!
Introduction
依然是解决老问题:体素化的需要解决信息损失 ,直接对点进行特征提取速度又不太行。这篇论文是 point-based SSD,想要使用 point 的精细特征,又不想要大量的计算,如果能够有不错的方法对点云进行筛选就好了
之前的 point-based 的采样方法都是 furthest points sampling (FPS) 基于距离的最远采样法,这样甚至会丢失一些重要的前景点。论文直接使用了一个网络来预测某个点是否为前景点,并基于这些预测结果进行下采样,这样就保证了重要的点不被丢弃
IA-SSD
Class-aware sampling
简单来说论文使用 MLP,将每个点的特征用于预测每个点的类别。损失函数为交叉熵损失
C 代表的是数据集的所有标签类别,$s_i$ 为标签的 one-hot 向量。在推理的时候,取前 k 个最高得分的点
Centroid-aware sampling
这是论文进一步提出的采样方法,让损失函数更聚焦于接近物体中心的点
其中 $f^,b^,l^,r^,u^,d^$ 代表的是这个点到 ground truth bbox 前后左右上下表面的距离
在推理/训练时,直接下采样得分最高的 top k 个点以及它们的特征继续进行选框预测
Centroid Prediction
继续给网络加入一些先验知识:让网络去做一些上下文的预测,能够让检测的结果更好,论文选择去做中心回归预测
先介绍一下公式中标记的含义:
- F 代表 ground truth boxes 个数
- S 代表(某 gt box 内)进行预测的点
- c 代表 center offset,i 代表第 i 个 gt box,j 代表在对应 gt box 中第 j 个点
- I 为示性函数,代表这个点有没有在某个 gt 中,也就是是否为前景点
可能上述的公式也不是特别严谨,但是整体还是很好理解的:
- 每一个(前景)点都有一个对应的 gt bbox,损失的计算都是点与各自的 gt 之间计算的。损失进对前景点进行,并使用前景点的数量进行归一化
- 增加了一个类似于方差的损失项,希望预测的中心尽量聚集在一个地方,也就是方差尽量的小
Centroid-based Instance Aggregation
有个预测的中心点过后,就可以基于这些中心点做特征提取。论文使用 PointNet++ 对点集进行 set abstraction。论文这里讲得特别的模糊,直接一句带过了,说是用了 local canonical coordinate system,但是我去看代码的时候好像没有看到对应的 canonical transformation。直接使用了预测得到的中心作为 new_xyz(需要做特征聚集的点)然后使用 PointNet++ 的方式抽取特征。特征来源是之前 SA 的输出,即经过 centroid-aware sampling 后的输出
Proposal
论文也是一句带过。应该就是使用点的特征预测 bbox,然后使用 NMS 做过滤。论文还使用了 corner loss,即是八个角点的损失函数。这个损失似乎越来越多在用了
Structure
整体看一下网络结构
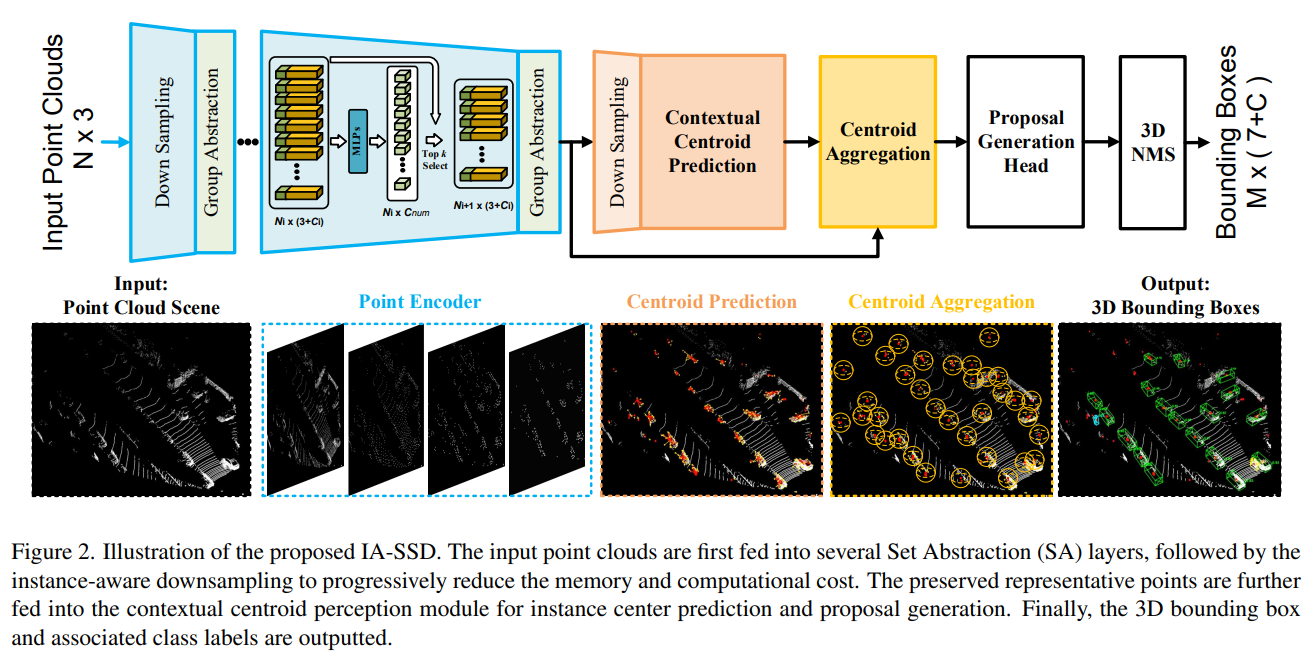
之前没提到的点:虽然论文的下采样核心是 centroid-aware sampling,但是在最开始依然采用的原始的 distance-based grouping & downsampling 用于提取特征,上图的 ... 就代表多层的原始 SA 模块
Experiment
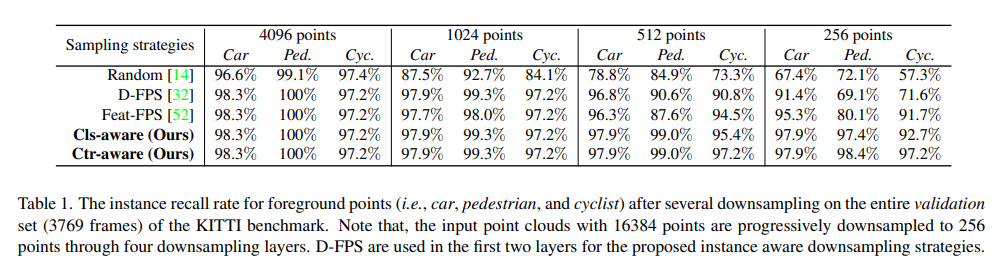
Effectiveness of downsampling
论文提出的 centroid-aware sampling 能够更好地保存前景点
Waymo & ONCE Results
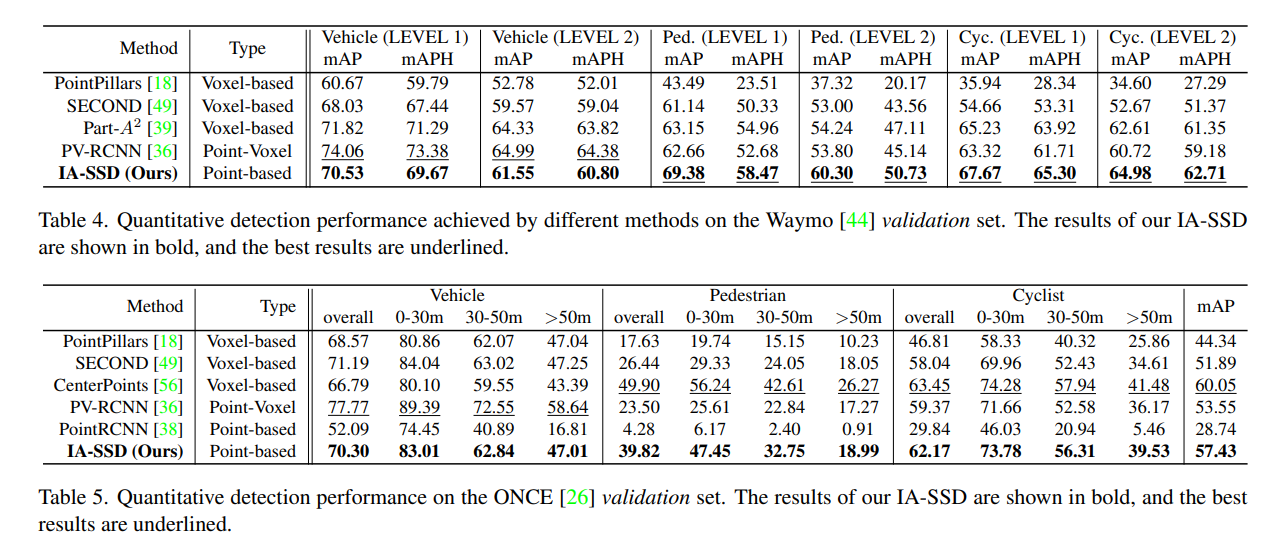
检测效果还是可以的,虽然不是最好的的,但 IA-SSD 胜在轻巧,在 KITTI 上能够通过高度并行达到 80 fps 的推理速度
TODO
代码解读,感觉这篇论文用到了很多 point-based 方法,也许以后会用到


