MMDetection3D & OpenPCDet
Install mmdet3d
可以参考 官方 doc 进行下载。其中提供了如何使用 conda 从零下载,但是环境不仅仅包含 conda 环境,还有 GCC, CUDA 等编译环境。所以更好的选择是使用 docker 进行安装,这样能够一步解决所有环境问题,专注于代码
# build an image with PyTorch 1.6, CUDA 10.1
docker build -t mmdetection3d docker/
docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmdetection3d/data mmdetection3d由于每次启动 docker 都要传入很多参数,所以在这里记录启动容器的命令,以后直接复制粘贴
docker run --gpus all --shm-size=8g -it -v /home/chk/data:/shared -v /home/chk/.Xauthority:/root/.Xauthority -e DISPLAY --net=host --name
# 其中 -e 和 --net 是为了设置图形化操作,在之后详细介绍在安装的过程中出现了两个问题
clone MMDetection3D 时网络出了问题,clone 失败了。再次尝试
docker build后成功其中有个小报错
ERROR: nbconvert 5.6.0 has requirement traitlets>=4.2, but you'll have traitlets 4.1.0 which is inco但是最终显示是成功安装,查了一下这个库,是用于将 notebooks 转为其他格式的,先暂时忽略。如遇到报错则尝试使用 pip 升级以符合条件
Nvidia-Docker
为了让容器能够使用 GPU,需要安装 Nvidia-docker,过程也比较简单,具体可以参考这篇 知乎
Verify
来运行官方 demo 验证是否安装成功
下载好 SECOND 模型,然后运行脚本
python demo/pcd_demo.py demo/data/kitti/kitti_000008.bin configs/second/hv_second_secfpn_6x8_80e_kitti-3d-car.py checkpoints/hv_second_secfpn_6x8_80e_kitti-3d-car_20200620_230238-393f000c.pth最后得到报错
Traceback (most recent call last):
File "demo/pcd_demo.py", line 4, in <module>
from mmdet3d.apis import inference_detector, init_model, show_result_meshlab
File "/mmdetection3d/mmdet3d/__init__.py", line 5, in <module>
import mmseg
File "/opt/conda/lib/python3.7/site-packages/mmseg/__init__.py", line 59, in <module>
f'MMCV=={mmcv.__version__} is used but incompatible. ' \
AssertionError: MMCV==1.3.8 is used but incompatible. Please install mmcv>=(1, 3, 13, 0, 0, 0), <=(1, 4, 0, 0, 0, 0).现在尝试升级 MMCV 以解决。修改 dockerfile 中的 mmcv 版本为 1.3.13,重新生成镜像和对应容器。由于目前实验室的 GPU 有其他人在跑项目,所以验证的时候发生错误 github issue
RuntimeError: /mmdetection3d/mmdet3d/ops/spconv/src/indice_cuda.cu 124
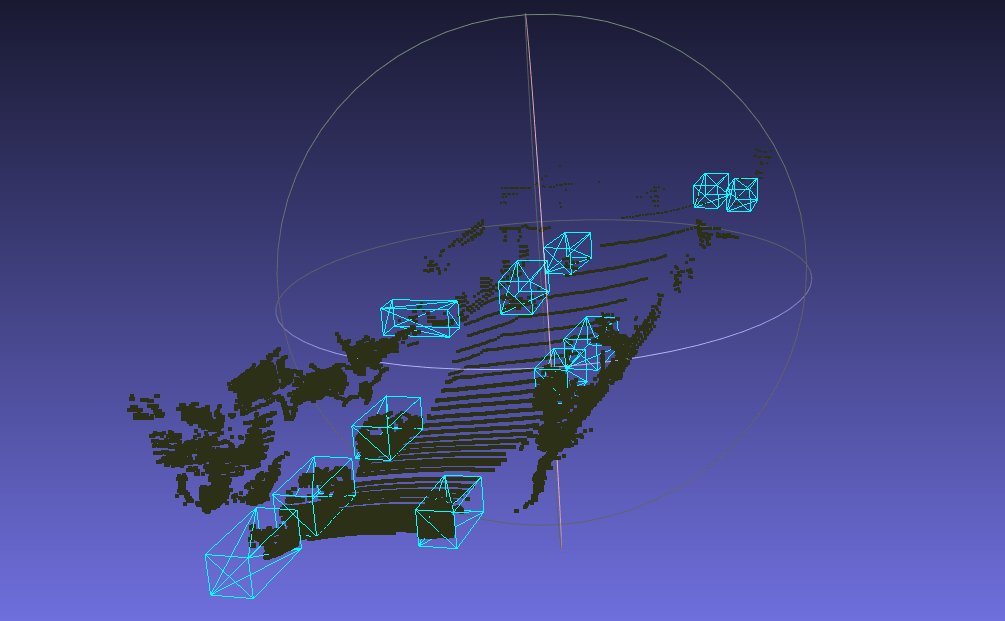
cuda execution failed with error 2应该是由于显存不足导致的,于是选择了一个较小的模型 PointNet++ 进行了验证,最终 demo 能够运行,故以上升级是有效的。在 MeshLab 中进行可视化查看 PointNet++ 分割效果

等服务器空闲了,测试了 SECOND,也可以运行
Work with VSCode
VSCode with container
想要 vscode 编辑 docker 容器中的文件,可以按照以下方法
下载 docker 和 remote-container 插件
在 side bar 中可以看到 docker 工具栏,可以轻松启动容器
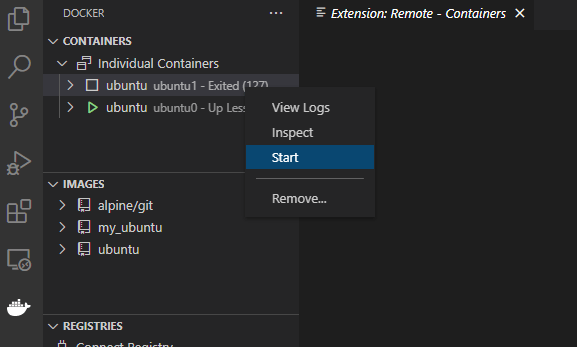
启动容器后,选择
Attach Visual Studio Code就可以打开新的窗口,新窗口的界面就像 vscode 在容器中运行一样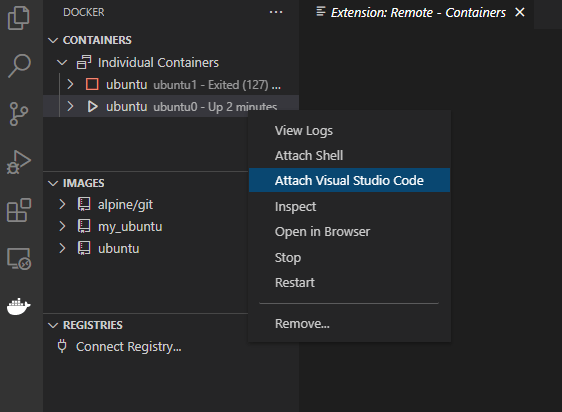
如果在 Linux 上遇到连接问题 error "connect EACCES /var/run/docker.sock" 这是由于 docker 权限造成,可以按照 官方提示 可以尝试解决。如果还不能解决,直接通过修改 docker.sock 文件的权限一步到位
sudo chmod 666 /var/run/docker.sockVSCode 免密登录
完成以下步骤即可:
生成本地 ssh-key,和 git 操作是一样的
ssh-keygen -t rsa将
id_rsa.pub复制到服务器主机~/.ssh文件夹下,将id_rsa.pub的内容加入到authorized_keys中cat id_rsa.pub >> authorized_keys重启 ssh 服务
service sshd restart
其他操作和一般 remote-ssh 是一样的,按默认填写配置文件即可,不需要配置 IdentityFile 关键字
Host Arbitrary_Nane
HostName Host_ip
User User_NameVSCode X11 forward
使用 X server 解决无法可视化图形界面的问题。一般来讲使用 ssh 连接到服务器后是不能使用图形化界面服务的,例如使用 firefox 浏览器。一些软件自带 X server,例如 MobaXterm,当连接上服务器后,可以直接在命令行输入 firefox,然后就能弹出浏览器窗口。如果电脑上没有 X server 则需要自行安装,或者直接把 MobaXterm 挂在旁边即可。更多科普内容参考 博客
现在在 VSCode Remote-SSH 上也支持了 X11 forwarding,可以通过以下步骤完成
首先修改配置 vscode settings.json 中 terminal.integrated.env.windows 字段,添加本地显示变量
"terminal.integrated.env.windows": {
"DISPLAY": "127.0.0.1:0.0"
}然后在 ssh 配置文件中加入相关字段
Host Arbitrary_Nane
HostName Host_ip
User User_Name
ForwardAgent yes
ForwardX11 yes
ForwardX11Trusted yes最后在服务器上指定 DISPLAY 环境变量
export DISPLAY="localhost:10.0"注意,10.0 这个数字是根据 .Xauthority 文件确定,可以通过 xauth list 命令查看。得到列表可能会比较长,我对这一块不是很了解…经验来看,关注的是最后一行,或者 unix:index 最小的那一行
user@linux xauth list
linux/unix:12 MIT-MAGIC-COOKIE-1 78cbc********************c64这里看到 unix:12 所以我们配置 DISPLAY 变量时应该为 export DISPLAY="localhost:12.0"
使用 xeyes 测试一下,如果看到一个眼睛窗口就成功了😎
Docker with GUI
如果能够在 Docker 中使用 GUI app 岂不是美滋滋?既然能够在 VSCode 中通过 X11 forward 协议运行图形界面,那么理论上 Docker 也是可以的!根据这两个博客:Link-1 Link-2 进行配置,意想不到地成功了,说明博客中的原理是正确的,只要将 Host 中的 X11 服务器分享给 Docker 就可以,具体步骤如下:
Share the Host’s XServer with the Container by creating a volume
--volume="$HOME/.Xauthority:/root/.Xauthority:rw"需要注意的是,每次登录的时 Host
.Xauthority是不一样的,如果直接复制该文件的话,要每次更新share the Host’s DISPLAY environment variable to the Container
--env="DISPLAY"Run container with host network driver with
--net=host
KITTI
使用 KITTI 数据集进行实验,下载通过 GRAVITI
将数据集放在一个文件夹下,全部解压
SECOND on MMDetection3D
先尝试测试一下经典的 backbone SECOND 能不能运行
Test SECOND
下载 SECOND 模型
根据 doc 生成数据集,其中生成了一些 pkl 文件用于存储数据集每个样本的相关信息,关于 pkl 文件可以参考 CSDN。下面是程序运行中最后的输出
load 2207 Pedestrian database infos load 14357 Car database infos load 734 Cyclist database infos load 1297 Van database infos load 488 Truck database infos load 224 Tram database infos load 337 Misc database infos load 56 Person_sitting database infosTest SECOND on KITTI val,其中
AP@0.5 0.5 0.5代表 bbox, bev, 3d 任务的 IoU 阈值分别为 0.5, 0.5, 0.5,列出 Car 相关的部分Result is saved to /tmp/tmp50avi_bh/results.pkl. Car AP@0.70, 0.70, 0.70: bbox AP:98.1839, 89.7606, 88.7837 bev AP:89.6905, 87.4570, 85.4865 3d AP:87.4561, 76.7570, 74.1302 aos AP:97.70, 88.73, 87.34 Car AP@0.70, 0.50, 0.50: bbox AP:98.1839, 89.7606, 88.7837 bev AP:98.4400, 90.1218, 89.6270 3d AP:98.3329, 90.0209, 89.4035 aos AP:97.70, 88.73, 87.34 Overall AP@easy, moderate, hard: bbox AP:84.0061, 75.7857, 73.6821 bev AP:80.2144, 72.7919, 69.1538 3d AP:76.7926, 66.6667, 62.3905 aos AP:80.79, 72.30, 70.19 {'KITTI/Car_3D_easy_strict': 87.45610724795893, 'KITTI/Car_BEV_easy_strict': 89.69046011671303, 'KITTI/Car_2D_easy_strict': 98.18389028596552, 'KITTI/Car_3D_moderate_strict': 76.75701107649772, 'KITTI/Car_BEV_moderate_strict': 87.45702960861706, 'KITTI/Car_2D_moderate_strict': 89.76058109581083, 'KITTI/Car_3D_hard_strict': 74.13015065869207, 'KITTI/Car_BEV_hard_strict': 85.4865455582404, 'KITTI/Car_2D_hard_strict': 88.78373491728972, 'KITTI/Car_3D_easy_loose': 98.33288257217502, 'KITTI/Car_BEV_easy_loose': 98.4400221898542, 'KITTI/Car_2D_easy_loose': 98.18389028596552, 'KITTI/Car_3D_moderate_loose': 90.02090501786836, 'KITTI/Car_BEV_moderate_loose': 90.12184507731126, 'KITTI/Car_2D_moderate_loose': 89.76058109581083, 'KITTI/Car_3D_hard_loose': 89.40349529357029, 'KITTI/Car_BEV_hard_loose': 89.62702775979791, 'KITTI/Car_2D_hard_loose': 88.78373491728972, 'KITTI/Overall_3D_easy': 76.79258397928281, 'KITTI/Overall_BEV_easy': 80.21439732105783, 'KITTI/Overall_2D_easy': 84.00606839712997, 'KITTI/Overall_3D_moderate': 66.6666643647041, 'KITTI/Overall_BEV_moderate': 72.7919003517221, 'KITTI/Overall_2D_moderate': 75.78568527747004, 'KITTI/Overall_3D_hard': 62.39046573028369, 'KITTI/Overall_BEV_hard': 69.15381069261458, 'KITTI/Overall_2D_hard': 73.68210872556001}
但是想要的预测结果 pred.obj 以及 result.pkl 好像并没有保存,并且查看了输出中的路径 /tmp/tmp50avi_bh/results.pkl 甚至都找不到这个路径 ,再次查看了官方文档,有以下描述
--show: If specified, detection results will be plotted in the silient mode. It is only applicable to single GPU testing and used for debugging and visualization. This should be used with--show-dir.
因为我在运行的时候只指定了 --show-dir,而 --show 和 --show-dir 需要一起使用。而没有看到 result.pkl 是因为我传入 --out 的参数为文件夹,应该传入一个文件。对于 --show 的使用,需要安装 open3d,pip install open3d 即可,我在安装的过程中遇到了一些错误,这里列出来
遇到错误
AttributeError: 'NoneType' object has no attribute 'point_size',原因可能是由于 open3d 版本问题,可以尝试更换版本pip install open3d==0.11,参考 github issue使用 open3d==0.11 后遇到错误
OSError: libc++.so.1: cannot open shared object file: No such file or directory,原因在于环境变量没有设置,参考 github issue 加入对应环境变量即可如果以上问题都解决了,但你的测试环境为远程服务器,没有图形界面 GUI,那么还可能遇到报错
RuntimeError: [Open3D ERROR] GLFW Error: X11: The DISPLAY environment variable is missing,可以参考 github issue 对if show部分的代码进行注释,或者如前文提到的方法,配置好 GUI 环境
Train SECOND
只能跑1个 batch_size
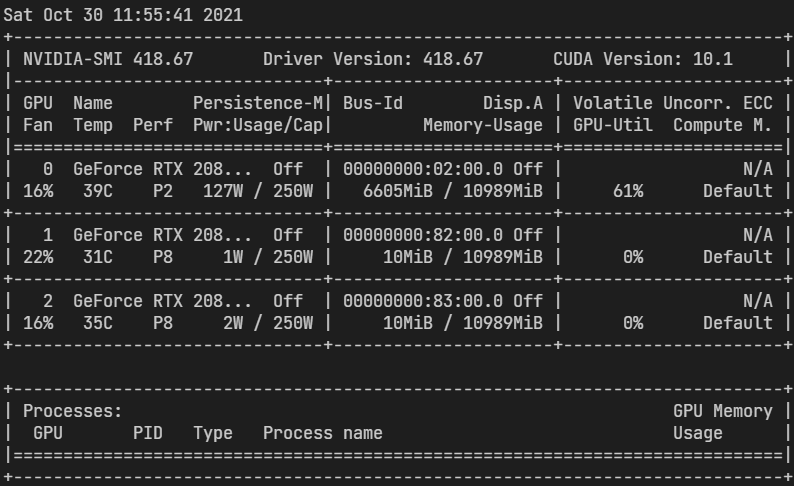
我认为我应该转战一下 OpenPCDet 项目,根据 PV-RCNN 论文
Our PV-RCNN framework is trained from scratch in an end-to-end manner with the ADAM optimizer. For the KITTI dataset, we train the entire network with the batch size 24, learning rate 0.01 for 80 epochs on 8 GTX 1080 Ti GPUs, which takes around 5 hours.
使用8个 1080Ti GPU 也能够跑24个 batch size,说明实验室的 2080Ti 至少每个能跑3个 batch size。然而 MMDetection3D 只能跑一个,确实太少了。现在需要对 OpenPCDet 进行更进一步的研究
———————————————-
OpenPCDet & spconv
首先面临的难题就是安装 OpenPCDet,最先想到的就是使用 docker 安装,也有人发布了 openpcdet-docker 但我下载下来后,感觉不太好用,最基本的 pip 命令都没有,当然也可能是我打开方式不对。尝试现成的 docker 失败后,只有自己逐步搭建了
Install spconv v1.2.1
安装 OpenPCDet 首先需要安装 spconv,这个部分也是花费了不少精力,到处都是困难啊😥而且由于 OpenPCDet 项目更新速度并不快,但是 spconv 已经更新到了 2.0 版本,老版本几乎已经停止更新了,所以想要安装老版本 spconv v1.2.1 也比有一些难度
Install by docker (deprecate)
首先想要通过 docker 来下载 spconv,但是由于 spconv 的镜像从不打 tag,如果根据原 Dockerfile 会默认拉取最新的镜像,所以 CUDA 版本并不是我想要下载的 10.1。而且实验室 Ubuntu 的 Nvidia Driver 版本不够新,所以更高版本的 CUDA 镜像是没办法启动的。于是就尝试根据 github 中最晚的更新时间,下载老版本的镜像,这里我安装的 tag 是

下载好该镜像后就能正常运行 CUDA 镜像了,然后就根据 OpenPCDet 官方 Install 文档进行安装
git clone https://github.com/open-mmlab/OpenPCDet.git
pip install -r requirements.txt
python setup.py develop但之后在安装 mayavi 库的时候出现了问题,因为需要使用 python3.7,而镜像是 python3.8,并且镜像没有 conda 命令,个人不是很习惯,于是打算放弃通过 spconv docker 安装。考虑使用 mmdetection3d 提供的镜像,作为基础镜像从零开始安装,因为该镜像的功能更多一些,环境更完整,其部分 Dockerfile 如下
ARG PYTORCH="1.6.0"
ARG CUDA="10.1"
ARG CUDNN="7"
FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0+PTX"
ENV TORCH_NVCC_FLAGS="-Xfatbin -compress-all"
ENV CMAKE_PREFIX_PATH="$(dirname $(which conda))/../"
RUN apt-get update && apt-get install -y ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*Install cmake
首先遇到的难题是安装 cmake,发现原来通过 pip 安装才是最快的方式,而且版本很新,参考 stackoverflow
(base) root@fb873089e53c:/spconv# cmake --version
cmake version 3.21.3
CMake suite maintained and supported by Kitware (kitware.com/cmake).Git clone
一定要使用 git clone ... --recursive 命令来 clone 该项目,--recursive 命令意思是这个项目还有一些子项目也需要 clone。并且需要加上 -b 参数指定 clone 的 branch,不然会默认 clone master 分支,而不是我需要的 v1.2.1 版本。整个下载的过程可能会很慢,强烈建议使用国内的镜像源,可以参考我的 git 笔记(题外话,自己就是因为 clone 操作没有弄对,在安装的时候除了好多错…心态爆炸)
Setup.py
运行 setup.py 进行编译,然后进入 ./dist 文件夹下载 xxx.whl 不同版本的 spconv 会有不同的 .whl 文件
python setup.py bdist_wheel
cd ./dist
python xxx.whlInstall OpenPCDet
下载好了 spconv 继续前往 OpenPCDet 项目继续安装吧
Install requirements
git clone https://github.com/open-mmlab/OpenPCDet.git 下载项目,然后安装环境
pip install -r requirements.txt 在下载 requirements 的时候发现莫名其妙地下载了最新版的 torch==1.10.0 替换了原来的 torch==1.6.0,requirements.txt 部分内容如下
torch>=1.1
kornia一般情况下 pip 是不会自动替换已经满足要求的包的,我使用了另一个 docker 也没有复现出这个错误过程,所以就暂时不要担心这个操作了。在 torch==1.10.0 的情况下运行 setup.py 可能遇到如下报错,更换对应的 torch 版本就好
RuntimeError:
The detected CUDA version (10.1) mismatches the version that was used to compile
PyTorch (10.2). Please make sure to use the same CUDA versions.并且由于 kornia 对于 Pytorch 低版本兼容性问题,根据 github issue 选择下载 kornia==0.5 版本,如果你不需要使用 CaDNN 也可以选择不下载 kornia。现在重新安装 torch==1.6.0 & kornia==0.5
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
pip install kornia==0.5Setup.py
运行 setup.py 进行编译
python setup.py developInstall mayavi
这个库是用于可视化的,其安装也有一些注意事项的,列举如下:
mayavi是需要图形化界面 GUI 的,到了这一步我不得不想办法让 docker 能够运行 GUI app,还好找到了方法,参照前文即可完成根据 知乎 下载
vtk==8.1.2,自动安装的为vtk==9.0.x,据说 在 python3.8 环境中似乎会出问题pip install vtk==8.1.2 # 自动安装的vtk是9,会产生冲突还需要下载
PyQt5以进行可视化pip install PyQt5之后遇到了一个与之相关的报错,也是困扰我很久,博客 解释是少了一些依赖库,可能是因为 docker 是一个精简的 ubuntu,没有完整的依赖库
通过
apt install python3-pyqt5下载了其相关的依赖库
通过不断地尝试不断地折腾可算是安装好了😀先来进行测试吧!
Demo on OpenPCDet
Demo
先将原来的 KITTI 数据集放到 data 目录下,已经使用 MMDetection3d 生成了基本数据,但 OpenPCDet 暂时还不需要生成,Demo 只需要原始数据集就可以了。准备好模型和数据集后,运行以下命令测试一下 SECOND
import os
CONFIG_FILE = '/OpenPCDet/tools/cfgs/kitti_models/second.yaml'
CKPT = '/OpenPCDet/checkpoints/second_7862.pth'
POINT_CLOUD_DATA = '/OpenPCDet/data/kitti/training/velodyne/000007.bin'
os.system(f'python demo.py --cfg_file {CONFIG_FILE} \
--ckpt {CKPT} \
--data_path {POINT_CLOUD_DATA}')运行 Demo.py 后获得了如下预测结果,看上去还挺不错的
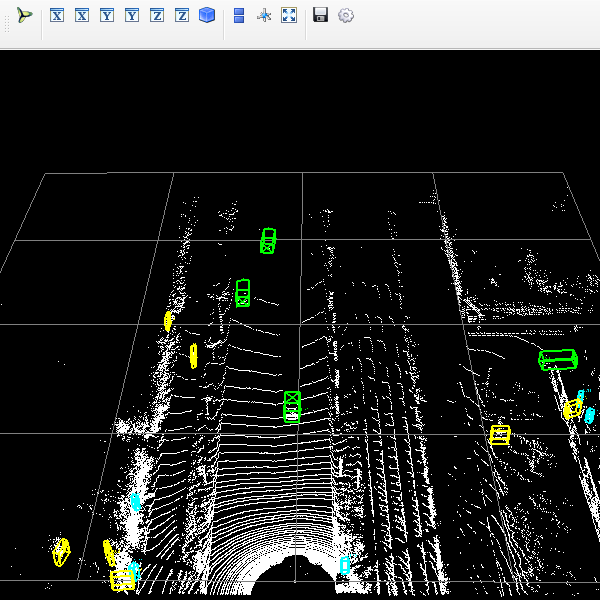
Test
直接测试 SECOND 在 KITTI 验证集上的结果,列出 Car 相关的部分
Car AP@0.70, 0.70, 0.70:
bbox AP:90.7803, 89.8999, 89.0433
bev AP:90.0097, 87.9282, 86.4528
3d AP:88.6137, 78.6245, 77.2243
aos AP:90.76, 89.77, 88.82
Car AP_R40@0.70, 0.70, 0.70:
bbox AP:95.6261, 94.1728, 91.7683
bev AP:92.4184, 88.5586, 87.6479
3d AP:88.6137, 78.6245, 77.2243
aos AP:95.59, 94.01, 91.52
Car AP@0.70, 0.50, 0.50:
bbox AP:90.7803, 89.8999, 89.0433
bev AP:90.7940, 90.1441, 89.5173
3d AP:90.7940, 90.0886, 89.4014
aos AP:90.76, 89.77, 88.82
Car AP_R40@0.70, 0.50, 0.50:
bbox AP:95.6261, 94.1728, 91.7683
bev AP:95.6751, 94.8476, 94.2478
3d AP:95.6623, 94.7450, 94.0537
aos AP:95.59, 94.01, 91.52
...
2021-11-01 11:48:15,756 INFO Result is save to /OpenPCDet/output/OpenPCDet/tools/cfgs/kitti_models/second/default/eval/epoch_7862/val/default
2021-11-01 11:48:15,756 INFO ****************Evaluation done.*****************与 MMDetection3D 的结果进行对比,整体上来看还是相近的
# OpenPCDet
Car AP@0.50, 0.70
3d AP:90.7940, 90.0886, 89.4014
3d AP:88.6137, 78.6245, 77.2243
Car AP_R40@0.50, 0.70
3d AP:95.6623, 94.7450, 94.0537
3d AP:88.6137, 78.6245, 77.2243
# MMDetection3d
Car AP@0.50, 0.70
3d AP:98.3329, 90.0209, 89.4035
3d AP:87.4561, 76.7570, 74.1302Train
查看一下 SECOND 训练的基本情况,这里改了一个配置:USE_ROAD_PLANE: False

训练速度还是不错的,此时的 batch size per GPU = 4 比 MMDetection3D 效率更高,下面是 GPU 使用情况
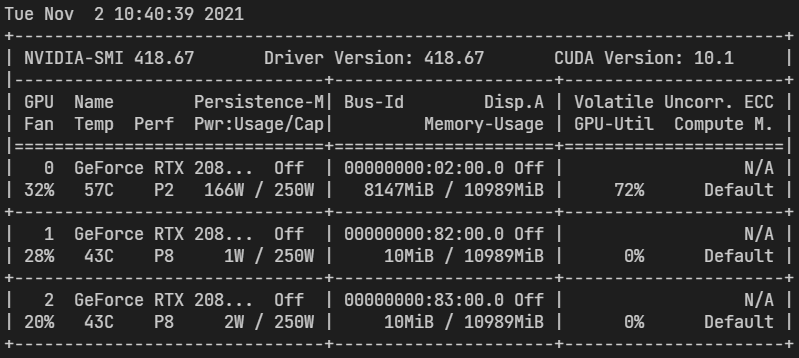
CenterPoint on MMDetection3D
现在尝试一下用 MMDetection3D 运行 CenterPoint,想要看一看 KITTI 数据集的结果,毕竟原论文中没有在 KITTI 上进行测试。有人在 github issue 也进行了一些尝试,原文作者也有项目 CenterPoint-KITTI,从实验结果来看,单阶段与 SECOND 效果差不多,并没有非常亮眼的表现,可能还需要进一步的微调
尝试在 MMDetection3D 上简单运行一下,然而似乎是显存不够的原因,没能够跑起来,后续再进一步研究吧


