Voxel R-CNN
Deng, Jiajun, Shaoshuai Shi, Peiwei Li, Wengang Zhou, Yanyong Zhang, and Houqiang Li. “Voxel R-CNN: Towards High Performance Voxel-Based 3D Object Detection.” ArXiv:2012.15712 [Cs], February 5, 2021. http://arxiv.org/abs/2012.15712.
Comment: AAAI2021
Introduction
这篇论文是 PV-RCNN 的一个后续研究,为了解决 PV-RCNN 中的推理速度问题,在改进之后速度能够达到 25 fps 的实时推理速度(on NVIDIA 2080 Ti),相比于前作的 8.9 fps(论文提供数据)提升了接近2倍。同时在准度上也超越了前作,虽然超越得不多,但是本论文的整个框架非常干净,几乎没有使用任何其他的技巧,后续提升空间非常大
许多现有的高性能 3D 探测器都是基于点 point-based,因为这种结构可以更好地保留精确的空间信息。然而由于无序存储,point-wise 特征会导致高计算开销。相比之下,基于体素 voxel-based 的结构更适合于特征提取,但是准确度不高。而这篇论文就打破了这个观念——即使是粗粒度的体素块也能很好地提供空间信息,精确的点云信息并不是高性能的关键点。之前 voxel-based 方法之所以效果不佳,是因为将三维体素特征图谱 3D voxel feature map 重塑为 2D BEV feature map 过后不再利用原来的三维体素特征了,而重塑的过程中就损失了空间信息
论文的核心重点为使用了 voxel RoI pooling 操作,通过提取 RoI 中的特征对选框进行细化,其中 RoI 特征来源于 backbone 中提取的 3D feature(这里我叫它体素化特征 voxel-wise feature),而非 PV-RCNN 中的点类特征 point-wise feature。去除了计算量庞大的点类特征提取,使得 Voxel R-CNN 推理速度大大增加,同时保持了优异的准确率
Voxel R-CNN Architecture
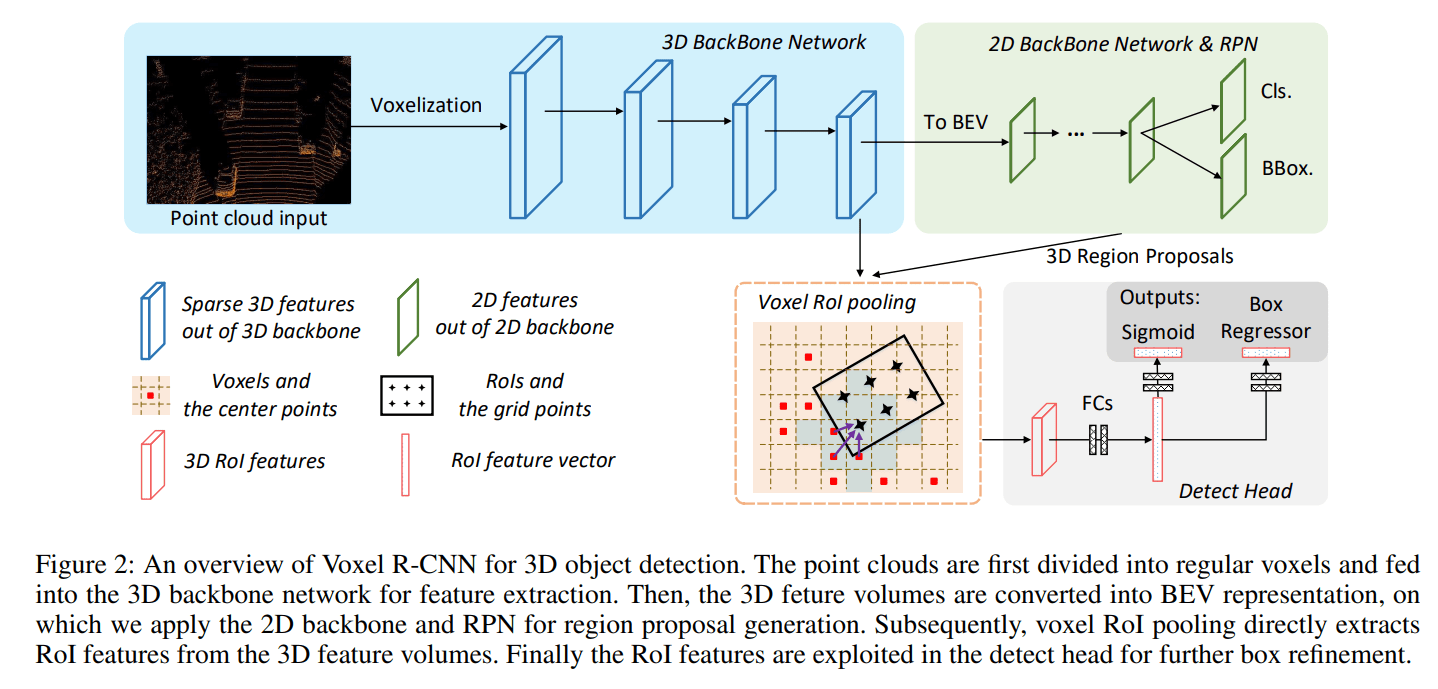
可以说这个示意图展示出来的结构非常干净,没有多余的技巧,就是 RCNN 框架的三部曲:
- 3D backbone特征提取
- RPN 提出选框
- 2-Stage 细化选框
3D backbone & RPN
直接使用 SECOND 作为其 backbone 网络提取特征,将得到的 3D 特征沿 Z 轴进行堆叠,重塑为 2D 俯视特征图谱 BEV feature map 作为 RPN 的输入。论文在第三节就这样一句带过 3D backbone,该 backbone 有4个阶段,每个阶段的频道数分别为 16, 32, 48, 64
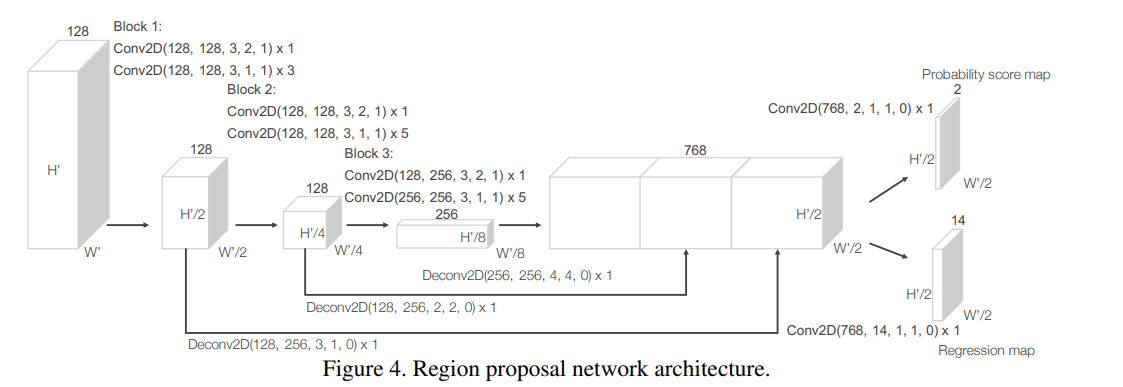
RPN 设计由两部分组成:
- top-down 特征提取网络,使用2个卷积块
- 对尺度特征融合结构,将不同分辨率的特征图谱进行上采样并连接起来,得到最终的特征图谱
最后时候该特征图谱去做分类任务和回归任务,这部分与 VoxelNet 中的 RPN 结构也是类似的,这里贴一下 VoxelNet 中 RPN 的示意图
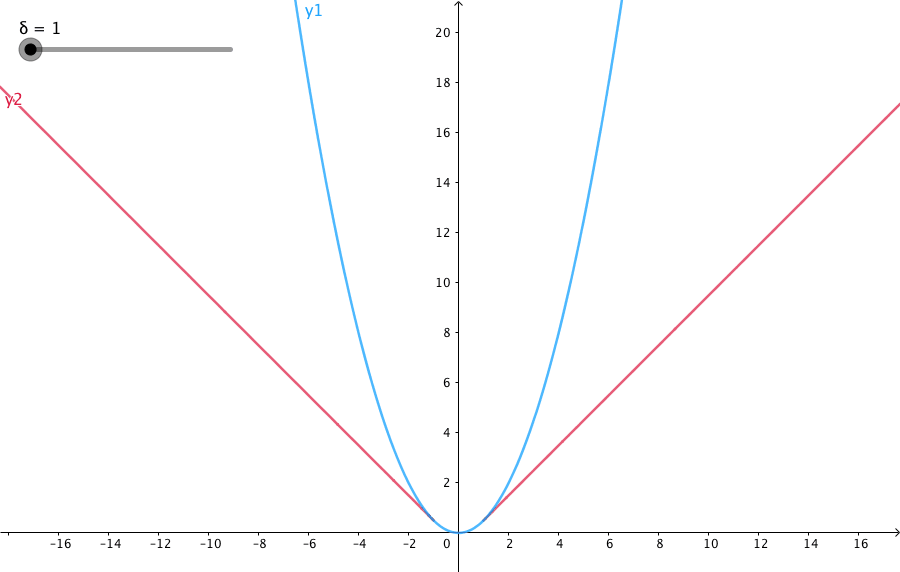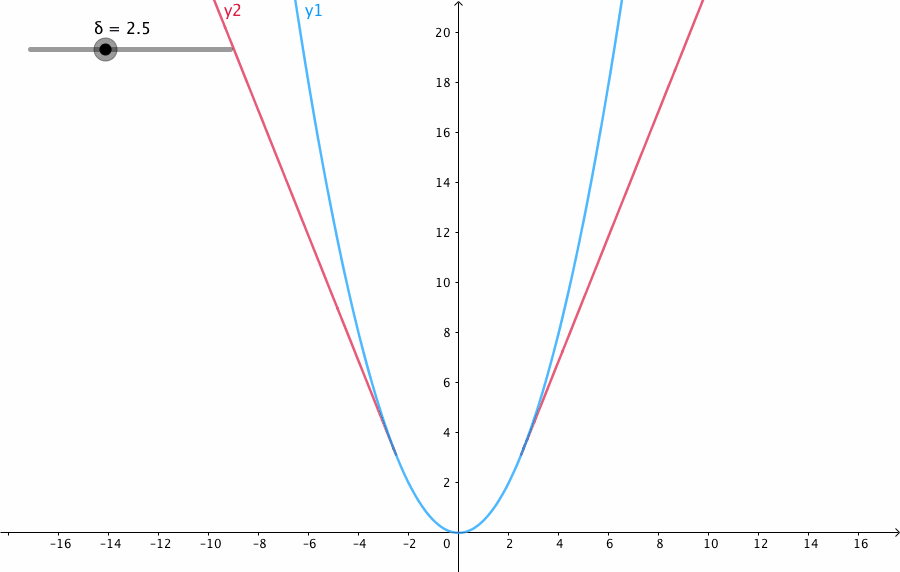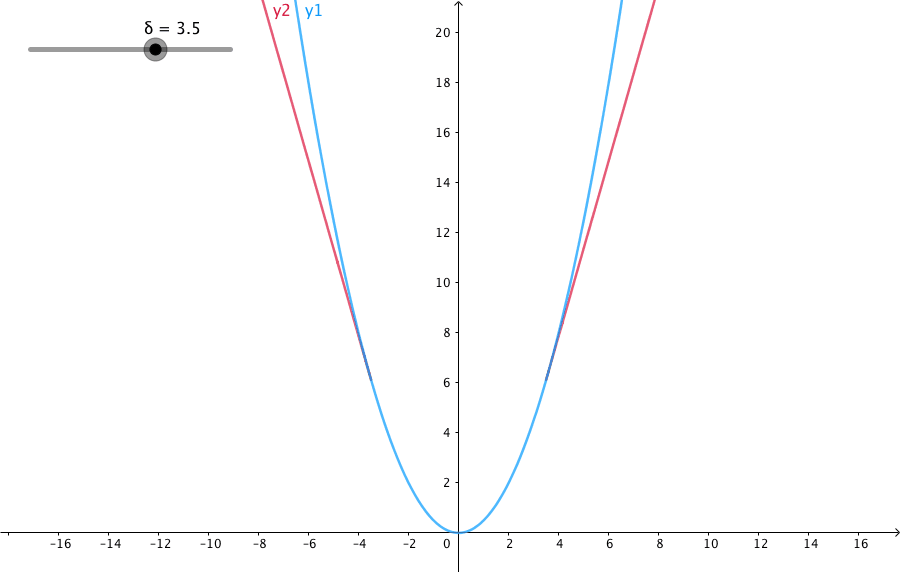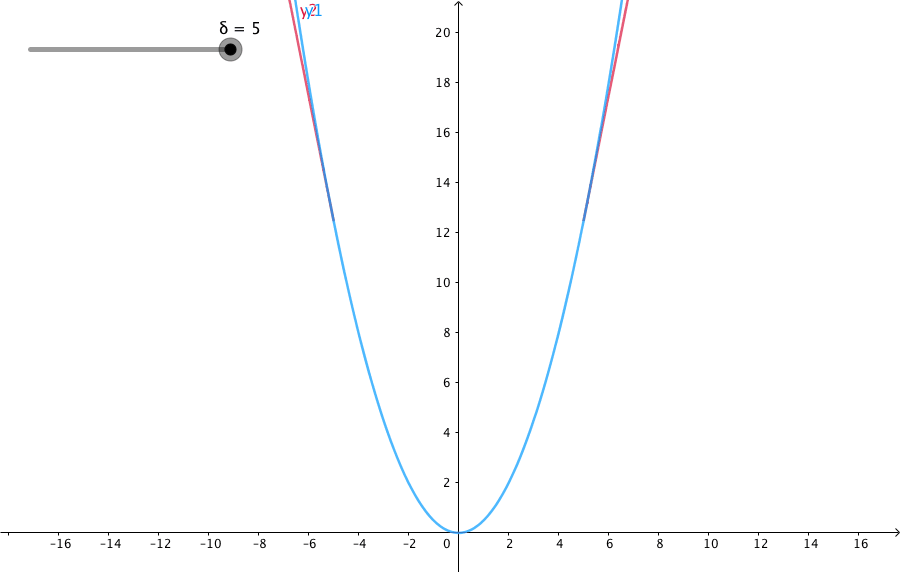
损失函数使用 focal loss 和 Huber loss,数学表示如下
其中 Huber loss 与通常使用的 smooth L1 loss 也是相似的,目的是为了减小奇异点的损失,其具体公式如下
Voxel RoI pooling
接下来就是论文核心操作了,即如何对提取出的体素化特征 voxel-wise feature 进行 RoI pooling
Voxel volumes as points
将每一个体素块 voxel volume 视作为一个点,该点的坐标为体素中心的坐标
其中 $\phi_i$ 表示该体素的特征
Voxel query
该操作为寻找某个体素附近的非空体素。由于体素的规范表达,两个体素之间的位置可以由他们的坐标 index 迅速计算,论文采用曼哈顿距离 Manhattan distance 表示两个体素 $\alpha,\beta$ 的距离
论文使用球搜索 ball query 来寻找附近的体素,时间复杂度为 $O(K)$,其中 $K$ 是(最大)邻居数。但这个 ball query 算法具体怎么实现的暂时还不理解…给自己留个坑吧,以后补机器学习和数据结构的时候看能不能填上!
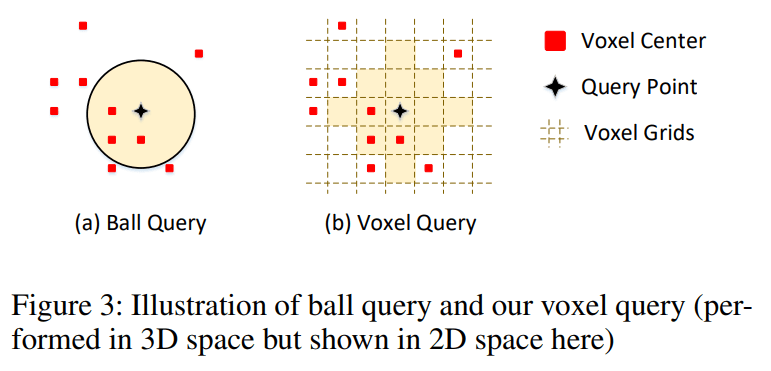
Voxel RoI pooling
首先将提议选框 proposal 平均分成 $G\times G\times G$ 个子体素块,将子体素块的中心点作为采样栅格点 $g_i$,用于进一步聚集体素特征。对于每一个采样栅格点,使用 voxel query,得到其邻居集合 $\Gamma_i = \{v_i^1,…,v_i^K\}$ 然后使用 PointNet 模块进行特征提取
在真正实施该 pooling 操作时,其 pooling 对象其实不是初始的体素化点云,而是 3D backbone 中最后两个阶段的 3D voxel-wise feature。并且对于每个阶段,设置了多个曼哈顿距离阈值以进行对尺度聚集 grouping,最后将不同阶段不同尺度的聚集特征进行连接得到最终的特征集
Accelerated local aggregation
论文使用了加速版本的 PointNet,区别与原始版本先做邻居搜索再进行特征提取,加速版本的 PointNet 将体素块的位置 $(x,y,z)$ 和特征 feature 进行分别处理,图示如下
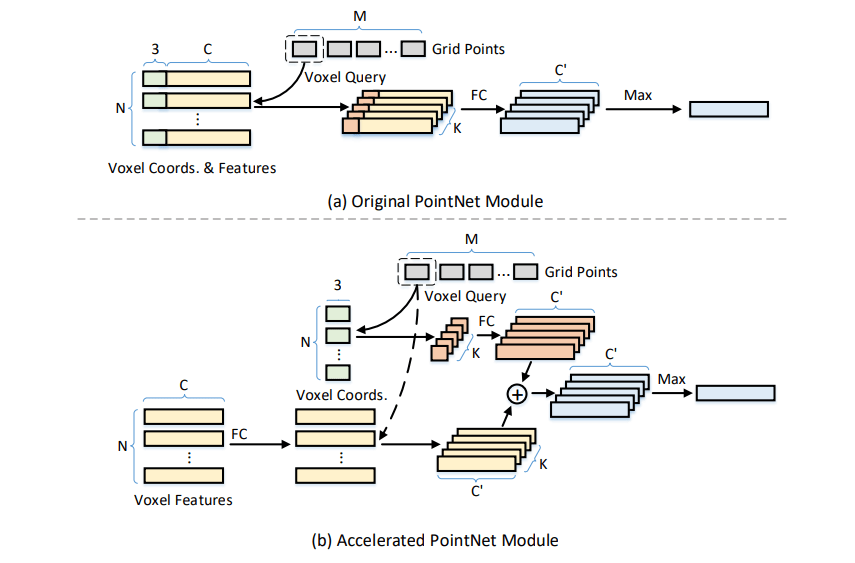
如果按照 PV-RCNN 中的方法进行点云特征聚合,则要先寻找附近的点 grouping,然后再对附近的点使用 MLP 做特征提取,这一过程的复杂度为 $(O(M × K × (C + 3) × C’ ))$,其中 $M=r\times G^3$ 为格点数 grid points,$r$ 为 RoI 数量,$K$ 为(最大)邻居数,$C+3$ 为输入特征维数,$C’$ 为输出特征维数
而论文将相对坐标与体素特征分离。给定权重为$ W ∈ \mathbb R^{C’ ,C+3}$ 的全连接层,论文将其分为 $ W_F ∈ \mathbb R^{C’ ,C}$ 和 $ W_C ∈ \mathbb R^{C’ ,3}$。由于体素特征与网格点无关,因此在执行 voxel query 搜索之前,直接在体素特征上应用了权重为 $W_F$ 的全连接层。然后,在 voxel query 之后,我们只将分组的相对坐标乘以 $W_C$,得到相对位置特征,并将它们添加到分组的体素特征中
加速 PointNet 模块的 FLOP 为 $O(N ×C ×C’ +M ×K × 3×C’)$,由于分组体素的数量 $M ×K$ 比 $N$ 高一个数量级,因此加速的 PointNet 模块比原始模块更高效。更直观地来讲,这样减少了很多由于重叠的邻居产生的特征提取操作
这部分内容引起了我对于 FC/MLP 作用的思考:MLP 将原始特征通过简单的非线性变换映射到新的特征空间中,其中伴随的维度变换是最直观的体现。以上方法做特征聚集竟然可以将输入分开来看待,这样做竟然不会影响表现,那为什么不对相对坐标也采用同样的操作,这样复杂度为 $O(N ×(C+3) ×C’)$ 会变得更小
Detection head
经过 voxel RoI pooling 过后每一个选框都有对应的特征向量集来表示,接下来就使用这些特征对选框进行细化。具体来讲,使用一个 shared 2-layer MLP 将 RoI 特征进一步做特征提取,将这些特征用于置信度预测和回归预测两个任务。回归分支预测从 3D 预测选框 proposals 到真实框的残差,置信度分支预测与 IoU 相关的分数。这些都是很常规的操作了,与 PV-RCNN 中是一致的,使用 binary cross entropy loss 和 smooth L1 loss,数学表示如下
Experiment
SECOND & PV-RCNN
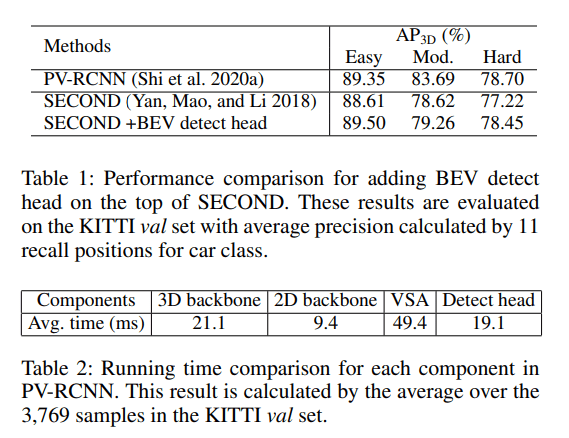
论文对 SECOND 和 PV-RCNN 进行了实验,两张图分别说明了:
- 2-Stage 的细化是有效果的,前作 PV-RCNN 的表现是相当不错的
- PV-RCNN 中花费了大量时间(超过一般)用于 voxel set abstraction (VSA) 操作,逐点操作 point-wise operation 计算量很大
KITTI
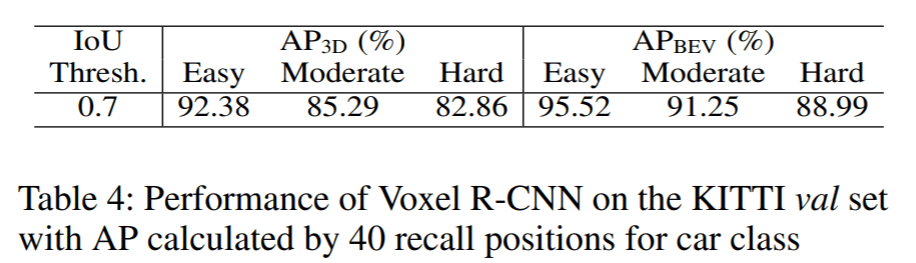
val set
test set
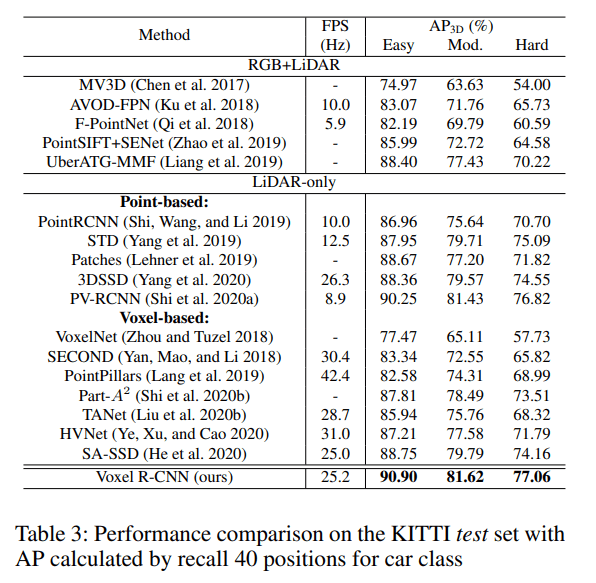
对标 SA-SSD,在准度和速度上均实现了超越
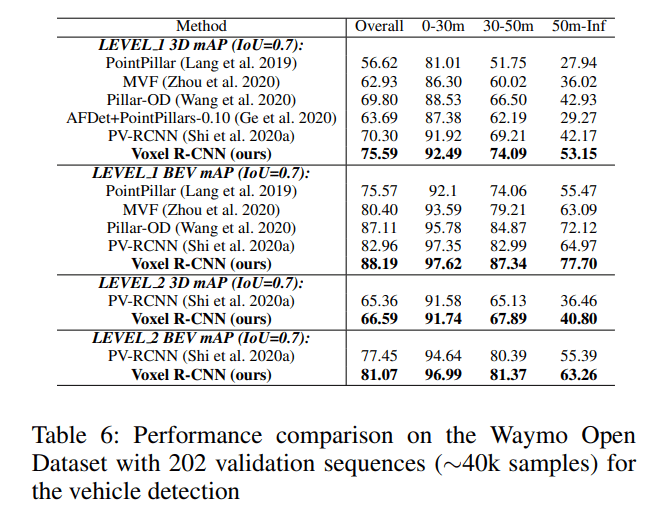
Waymo
Ablation study
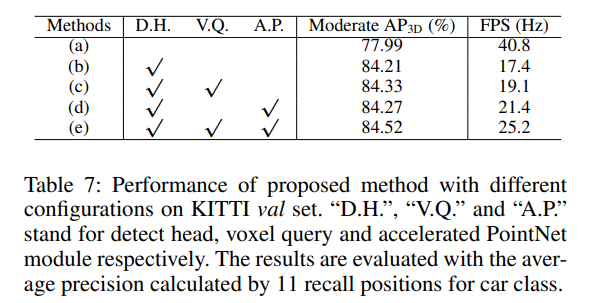
其中不使用 voxel query 则使用 ball query 替代,区别请参考 voxel query 一节 Figure 3。可以看出 voxel query 稍微加快了速度也稍微提升了准确率,对于速度提升最大的是 accelerated PointNet 操作。对于准度提升最大的则是 2-Stage detection head,但同时也让速度下降一半多
Conclusion
这一篇论文的中心思想很明确,就是直接使用 voxel-wise feature 对预测选框进行细化,然后加速了 PointNet 特征提取操作,二者的结合形成了本文的核心 voxel RoI pooling。Voxel R-CNN 在速度和准度上全面超越了前作 PV-RCNN,重点在于其网络结构非常干净,没有使用过多的辅助技巧,如果将其他论文中的提升技巧结合到本论文中(例如语义分割),应该会有更多的提升,期待之后的发展


