Windows 的软件
Listary,搜索神器
potplayer + 简洁皮肤定制,该播放强比你想象中更强大,对各种格式都有很好的兼容性,还能实时翻译字幕以及录制视频
bandzip
bilibili 直播姬,OBS,对于 OBS 的简要教程放在后面
clash
滴答清单
chrome,油猴插件:Bilibili Evolved,zotero,google translate,youtube 双语字幕, translatesubtitles.co/
印象笔记
typora
latex
vscode
zotero
推荐 plugin: zotero citation counts manager 用于爬取文献引用。想要将 zotero 的文献进行转移时,只需要转移 storage 及其 zotero.split 文件即可
zotero 也有很方便的 word 插件,在需要的文献后面 add/edit citation 就可进行插入,然后在文末 add/edit bibliography 即可
- 为了保障 zotero 云端的空间,我选择了在拉取数据时不下载 pdf,这样空间就完全够用了。将 pdf 文档单独存放到其他文件夹中,并使用自己的脚本进行重新命名,解决。脚本代码放在后面
git,当 github 下载文件慢时请搜索 github 镜像资源
百度网盘 阿里云盘
ps pr
WinSCP,Xshell,MobaXterm(强烈推荐,可以替代 WinSCP & XShell)
SpaceSniffer,查看存储空间
utorrent
LinuxReader,方便双系统在 Win 中获取 Linux 系统的文件
Snipaste,好用的截图工具,以后再也不用打开 QQ 再截图了😎
Drawio & Excalidrao,用于画流程图/网络架构
Utools,介绍自己常用的功能:中键快速用 cmd/vscode 打开文件夹;剪切板查看历史剪切记录;网页快开能够实现迅速搜索;中键显示翻译;OCR 图片转文字;Linux 命令查询插件;图片压缩插件;
OBS 简要教程
主要根据 bilibili 进行学习
界面介绍
来源
首先 OBS 最基本的功能就是录制电脑屏幕/窗口。我们需要告诉 OBS 需要添加哪些信息源,这就是来源窗口的功能。比如上图中添加了显示器采集,这个来源就能够记录你的屏幕内所显示的内容
场景
OBS 在一个场景中可以添加多个来源,并且调整这些来源如何显示各个来源,比如我们希望最终的画面左边为显示器采集内容,右边为游戏源。我们也可以创建多个场景,在直播的时候可以直接选择某个场景,或者在场景之间切换
混音器
用于采集电脑声音和麦克风声音
设置
掌握以上逻辑就能很好地使用 OBS 了,当然进一步使用肯定要对设置进行调整,以下为我的设置
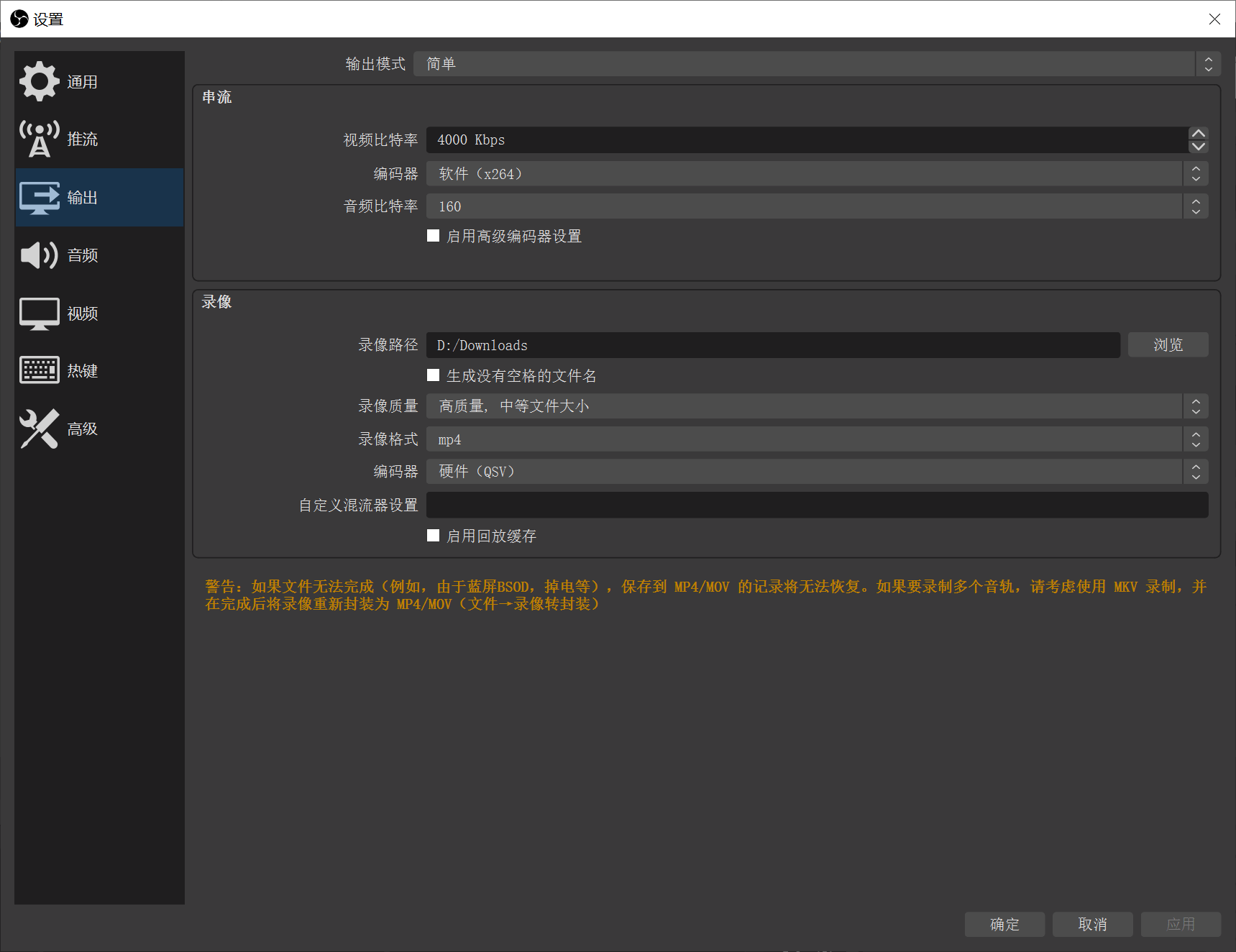
比较重要的就是输出设置,串流代表你直播时采集画面的质量,录像即代表录制画面的质量。下面看看这几个参数
- 码率,越高视频质量越高,一般推荐 2k-8k 之间
编码器,一般有两个选项,x264 代表用 CPU 进行编码,其他硬件则多为 GPU
音频比特率,一般为160或320
面板中的其他设置,例如:推流用于设置直播平台服务器,视频还可以进一步设置视频的分辨率、帧数
Arxiv pdf rename script
我希望重命名 arxiv 下载的 pdf 文件,不然全是数字 id 命名很难进行管理,所以自己写了一个 python 脚本,该脚本是使用 pdf 文件名作为 id 查询 arxiv 上论文的标题、作者、发布时间,然后重命名原 pdf 文件。使用方法如下
下载 arxiv 三方库
pip install arxiv将你的 pdf 放在一个文件夹中,例如
archive将脚本
rename.py放在与archive同级的目录,如下- archive - xxxx.xxxx.pdf - xxxx.xxxx.pdf - rename.py运行
python rename.pyimport arxiv from pathlib import Path # PDF dir if __name__ == '__main__': archive = Path('./archive') for pdf in archive.glob('*.pdf'): id = pdf.stem if len(id) > 20: continue # ignore processed pdf search = arxiv.Search(id_list=[id]) result = next(search.results()) # process title title = result.title.replace(':', ' -').replace('?', '').replace('*', '')[:220] # process time and author time = result.published.year author = result.authors[0].name # rename path rename = archive / f'{time}_{title}_{author}.pdf' print(f'{id} -> {rename.name[:30]}...') pdf.replace(rename)


