ViT & MAE & Swin Transformer
Dosovitskiy, Alexey, et al. “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale.” ArXiv:2010.11929 [Cs], June 2021. arXiv.org, http://arxiv.org/abs/2010.11929.
He, Kaiming, et al. “Masked Autoencoders Are Scalable Vision Learners.” ArXiv:2111.06377 [Cs], Dec. 2021. arXiv.org, http://arxiv.org/abs/2111.06377.
Liu, Ze, et al. “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows.” ArXiv:2103.14030 [Cs], Aug. 2021. arXiv.org, http://arxiv.org/abs/2103.14030.
想要把这三篇论文统一整理一下。ViT 是视觉 transformer 的奠基作之一,而 MAE 和 Swin 是最近的强势论文。在了解 transformer 之前老是被这个东西的计算时间给吓到,要什么几百个 GPU/TPU 跑个几天才跑得出来,但了解之后我似乎觉得不是这么回事。Transformer 模型可以做的和普通卷积网络一样小的,计算量也是差不多的,不过通常为了刷榜会使用更大的模型和超大的数据集,这就导致了训练时间炸裂!但实际上 transformer 是一个非常好的结构,效率并不低,应当重视起来!!
ViT
Transformer 到底有什么优越性?Transformer 能够更好地处理如下难题:
- Occlusion,遮挡
- Distribution shift,分布偏移
- Permutation,排列
简单来讲这些性质来源于 transformer 的全局建模能力(具体原因咱也不知道哈😀)除此之外 transfomer 目前似乎还未观察到性能饱和的现象,数据集越大,模型越大,效果越好
但是在一些不那么大的数据集上训练 ViT,效果反而不是那么好,论文认为这是因为数据集少,transformer 难以学到最好的特征。CNN 因为有两个先验知识:1. 平移不变性;2. 相对位置,所以使用较小的数据集能够有更好的表现。但是随着数据集的增大,transformer 的威力就全面爆发了
由于自注意力是平方复杂度的增长,所以直接应用到 cv 上有一定困难,前人尝试过的方法:1. 在 window 上做自注意力;2. 使用 sparse transformer,为全局注意力的近似;3. 轴注意力,先在横轴上做自注意力,然后在纵轴上做自注意力
ViT Model
如果你了解 BERT & Tansformer,ViT 的模型理解起来根本没有难度
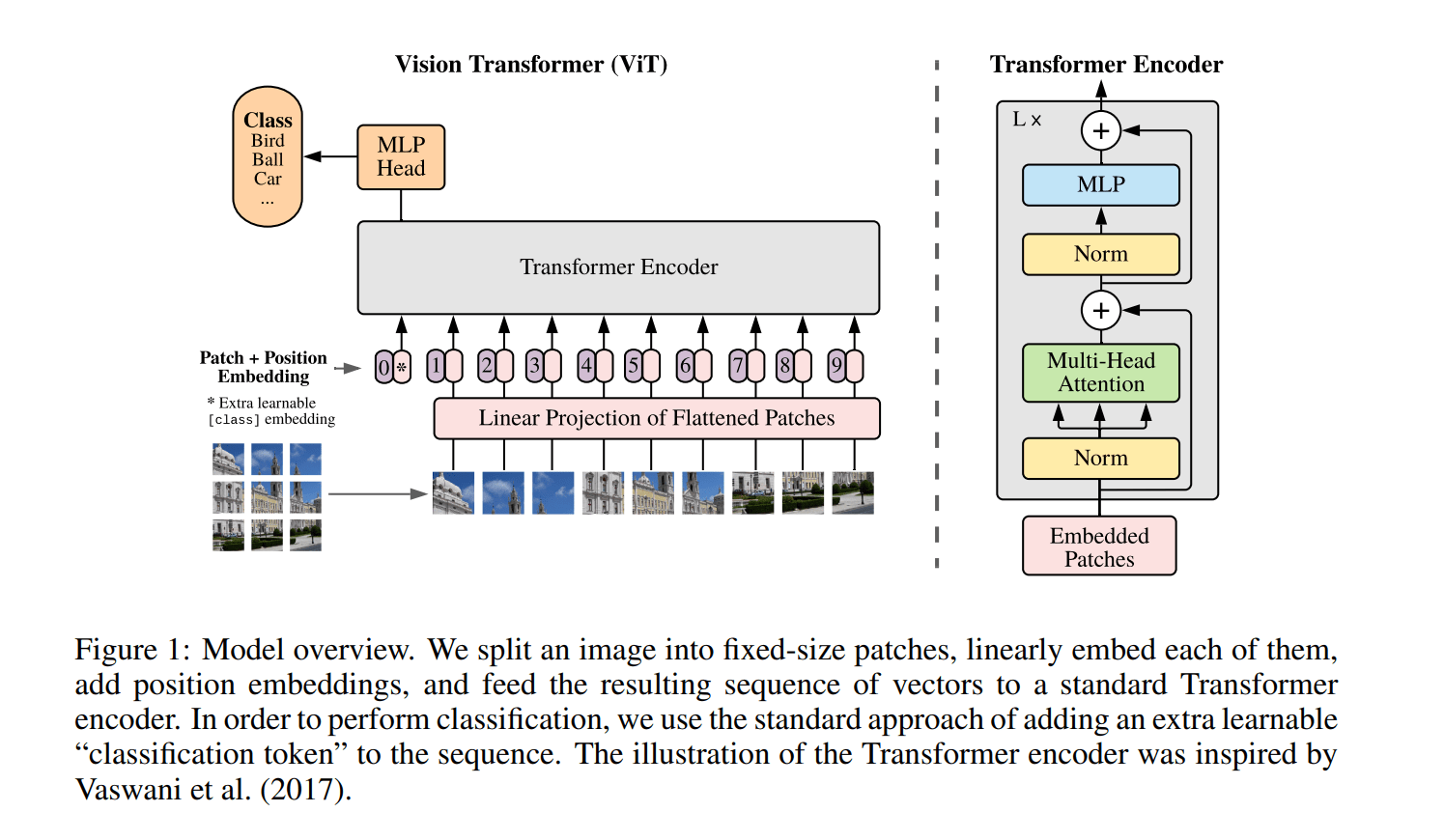
我们按照前向方程的顺序来逐个看看:
- 将图片分割为 Pathes,每一个 Patch 为 16x16 大小的子图,将该子图展开为 16x16x3 = 768 维的特征。假设原图大小为 224x224 那么能够得到 196 个子图,我们把每一个子图就当作一个 token,此时有 196 个维度为 768 的 token
- 增加 cls token 到 Patch token 中,用于之后的分类任务(不一定非要使用这个 cls token 结构,也可以是对其他 token 使用 global average pooling。论文这么做是为了和 BERT 尽量靠近,排除是视觉中的 trick 带来效果提升)
- 将 Patch token 输入到一个全连接层进行维度转换/线性映射
- 生成位置编码。类似于 BERT,设置一个可学习的位置编码,维度与 Patch token 的维度相同。将位置编码与 Patch token 加起来,得到 input
- 将 input 输入 Transformer encoder
- 使用 cls token 处获得的特征,输入到全连接层做分类任务
ViT 在微调的缺点
在进行微调时,使用不同尺寸,但是由于预训练时位置编码大小是固定,所以预训练的位置编码不好使用在微调中。一个简单的解决方法就是用插值
不同大小的 ViT
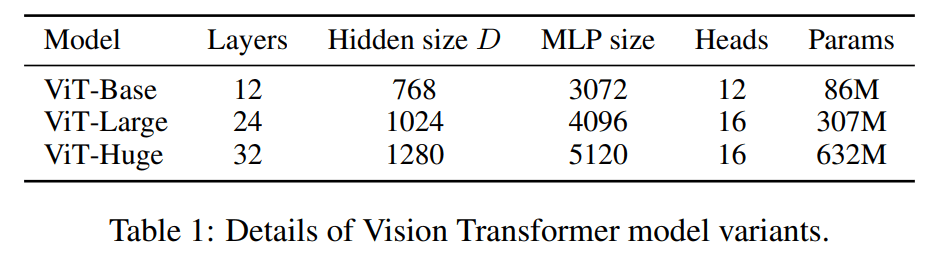
之后的 vision transformer 很多都时这样的命名方式,后面的 B, L, H…都代表模型的大小 base, large, huge, tiny, small….
ViT Experiment
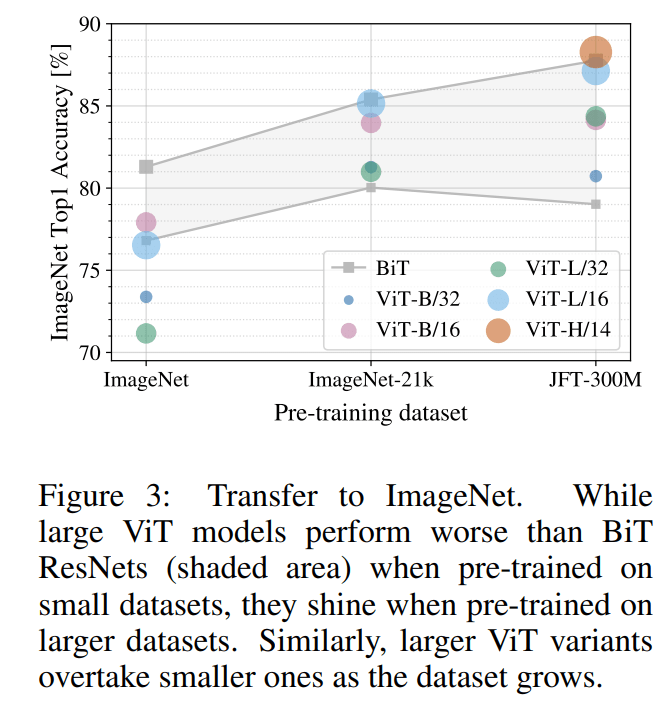
整篇论文的核心实验结果:小数据不如 resnet-based 模型,大数据效果拔群。所以这里就有一个潜在的研究方向:transformer 在小样本上的学习
MAE
Masked Autoencoders Are Scalable Vision Learners 是一篇比较新的文章(2021/11),主要整理一下思想,细节部分需要看代码,代码也是今年年初开源(2022/1),MAE pytorch。标题中的 scalable 表示模型能够适用于非常大的数据集,而标题中的 auto 不是自动的意思,仅仅表达”自” self,更具体一点表示自监督
MAE Model
MAE 的模型图示是比较清晰的,看完就能有一些概念了
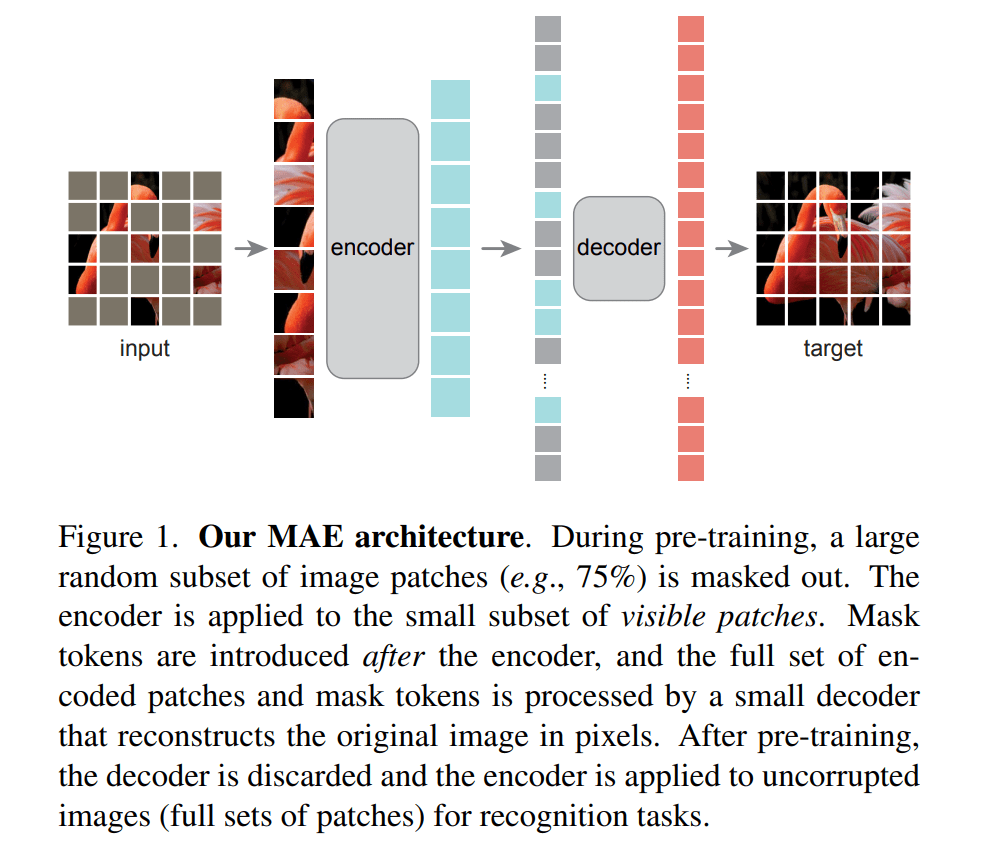
还是用语言来总一下:
- 将图片分为 patches,然后随机掩盖掉大部分 patches (75%)
- 将没有掩盖的 pathes,按照 ViT 中的方法进行编码(positional + patch embedding)
- 加入 masked patches 到已经编码好的 patches,此时 mask patches 使用一个统一的可学习向量表示。并且顺序是按照初始分割顺序
- 再将所有 patches,按照 ViT 中的方法进行解码,但使用一个轻量的 ViT
MAE Motivation
MAE 的设计逻辑写得是真的清晰,将视觉中的自监督难点与 NLP 中的自监督进行比较,解释为什么视觉中的自监督比较难:
- 视觉领域之前难以提出像 NLP 里的 token 概念。但现在已经被 ViT 解决
- 视觉中的信息是冗余的。一个图片去掉少量像素点,不妨碍这个图片的整体表示。但是一句话里去掉一个词,可能整个意思都不明确的。这是 CV 和 NLP 在信息密度上的差别
- 对于解码器,NLP 使用一个简单的 MLP 进行解码去预测 masked token,而这个 token 所表示的语义信息是很丰富的。但是 CV 需要预测的是一个原始的像素点的话,其语义信息并不那么明确,所以需要比 MLP 更强大的解码器
以上就是 MAE 的设计逻辑,对于每个难点精准出击!
MAE Experiment
Ablation Study

fine-tuning 代表整个网络的参数都可以调整,linear probing 只能调整最后的输出层,两种不同的策略效果相差很大!下面这张图比较了 MAE 和 ViT
MAE vs. ViT
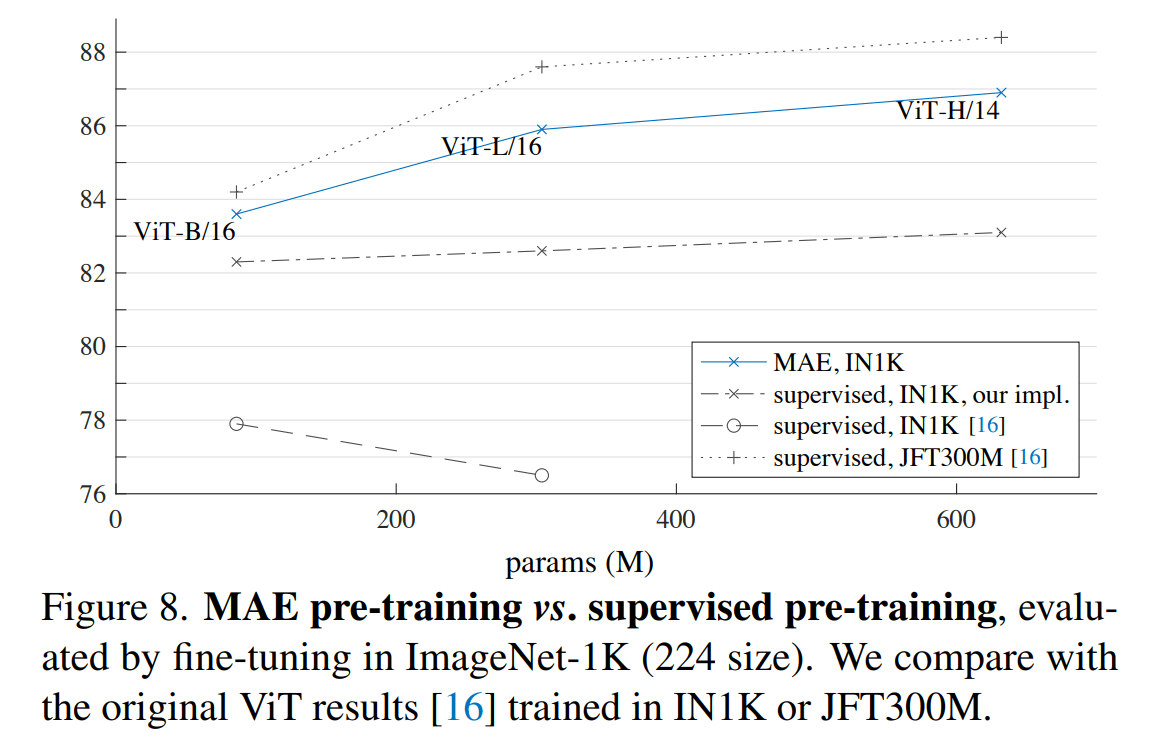
虽然只看结果似乎 MAE 落后于 ViT,但需要注意的是 MAE 只在 ImageNet-1K 上做的预训练,而 ViT 在 JFT 上做的预训练(这是一个超大的数据集),不知道在更大的数据集上进行预训练 MAE 会发生什么呢?
MAE vs. MoCo
微调层数实验

直接结果比较
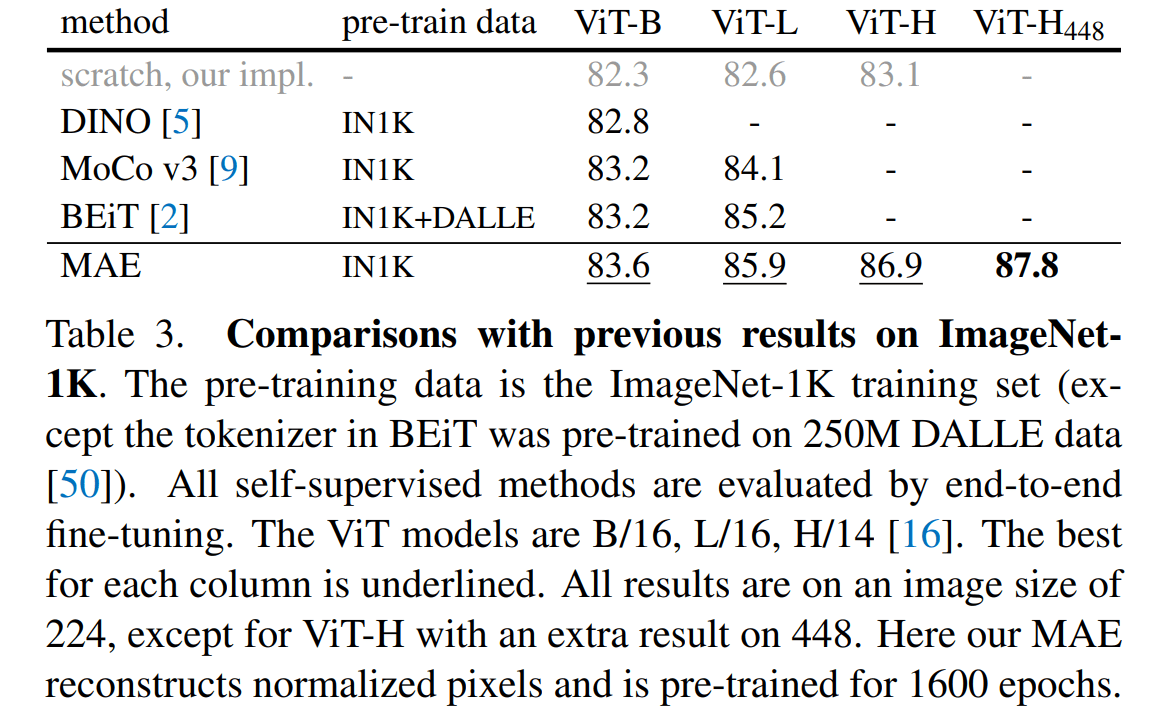
MAE 可以说是比 MoCo 更加强劲的无监督学习方法(但是 MoCo 的轻量好用也是无可争议的)。从第一张图可以看到随着解冻的层数增加,MAE 迅速超越了 MoCo。这说明了 MAE/ViT 不是一个线性可分的结构,最后几层的 transformer block 是和任务紧密相关的。另一个也说明了底层所学习的特征是通用的,因为随着解冻层的增加,表现的提升增加缓慢
论文在相关工作里提了一句对比学习:对比学习更依赖于代理任务和数据增强(再联系上 mean teacher,我似乎感觉:半监督和无监督的区别再慢慢减少?)
Swin
Swin-Transformer网络结构详解 Swin Transformer论文精读
看了上面两个讲解视频,最大的感受就是:好多好多 trick 啊!!自己理解起来也没有特别清晰…难道以后要使用 swin 作为之后的主要骨干吗?回想起 ResNet 简洁,我实在是难以接受…这里就简单整理一下里面的核心思想吧
Swin 认为 Transformer 在视觉里的两大难点:
- 处理多尺度信息
- 处理高分辨率图像
这两者个难点使用移动窗口在 CNN 里是很好的解决的(为什么不能也使用移动窗口?可能是计算上的原因吧),论文就想尽办法,把 CNN 上的“窗口”往 transformer 里面搬:
- 对于高分辨率问题,也是计算量问题,Swin 直接在一个固定的 window 内部做自注意力即可
- 对于多尺度问题,Swin 使用了一个 Patch Merging 的方法,这样就能够进行像 CNN 一样的下采样,获得更大的感受野
- 对于固定 window 的方法有局限性:window 之间的交互没有了。所以提出了 shifted window 自注意力
- 对于提出的 shifted window 自注意力,由于各个大小的块不一样了,提出了更有效的循环位移+掩码计算方法
- 使用了一个不太好理解的相对位置编码,作为偏置加入到权重当中,而不是像 ViT 一样做 embedding
可以看到后面三点都是针对第一点的 idea 做的补充,并且都不是特别好理解…但最终 Swin 的效果就是巨好!简直就是无情的屠榜机器!并且在各式各样的性能优化下,计算量和同等大小的 ResNet 是差不多的,希望大佬们继续努力,下放更好的技术给我们用555


