Point-GNN note
由于对于GNN没有过多的了解,并不能感受到GNN相对于CNN有极大的优势。相反的,在其中设计的很多结构,与使用CNN处理是相似的,最核心的观点就是捕捉到 (multi-scale) local feature,这篇笔记仅潦草记录一下
Introduction
构建图的方法:以点作为图的顶点,将每个点和附近的点相连形成边
We encode the point cloud natively in a graph by using the points as the graph vertices. The edges of the graph connect neighborhood points that lie within a fixed radius, which allows feature information to flow between neighbors.
A graph neural network reuses the graph edges in every layer, and avoids grouping and sampling the points repeatedly.
几个特点:
- Use a graph representation can preserve the irregularity of a point cloud
- Unlike the techniques that sample and group the points into sets repeatedly, we construct the graph once.
- The proposed Point-GNN then extracts features of the point cloud by iteratively updating vertex features on the same graph. Our work is a single-stage detection method.
Point-GNN for 3D Object Detection in a Point Cloud
our method contains three components:
(a) graph construction,
(b) a GNN of T iterations, and
(c) bounding box merging and scoring.
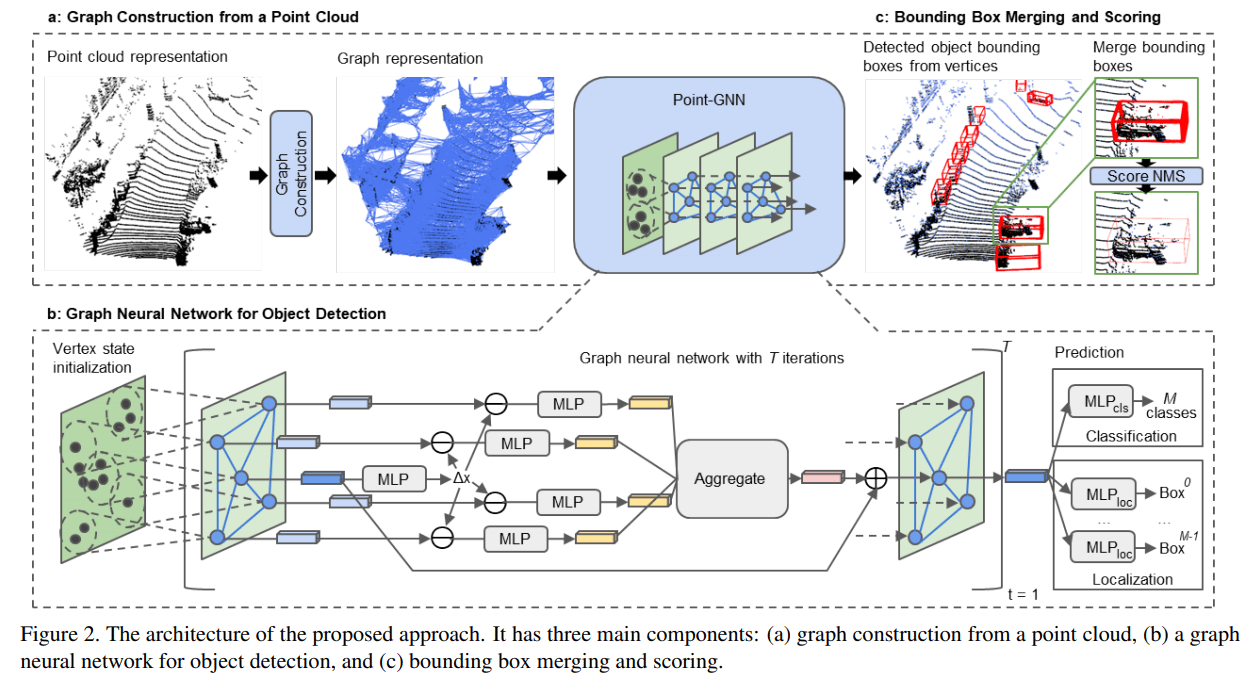
Graph construction
Formally, we define a point cloud of N points as a set $P = \{p_1, …, p_N \}$, where $p_i = (x_i, s_i)$
$x_i$是坐标,$s_i$为state value可以看作feature
we construct a graph G = (P, E) by using P as the vertices and connecting a point to its neighbors within a fixed radius r
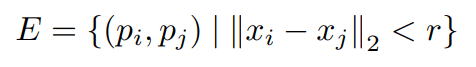
由于点太多了,需要下采样
we use a voxel downsampled point cloud $\hat{P}$ for the graph construction.
为了保留原点云的信息,先用PointNet将点云encode(文章说不用grouping and sampling其实到处都在用)
To preserve the information within the original point cloud, we encode the dense point cloud in the initial state value si of the vertex. More specifically, we search the raw points within a r0 radius of each vertex and use the neural network on sets to extract their features.
Graph Neural Network with Auto-Registration
GNN一般迭代过程
A typical graph neural network refines the vertex features by aggregating features along the edges.
在 $(t+1)^{th}$ 迭代中,顶点更新公式为
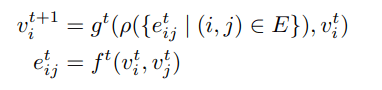
where $e^t$ and $v^t$ are the edge and vertex features from the $t^{th}$ iteration.
$f^t(·)$ 通过两个顶点的特征来更新边的特征
$\rho(·)$ 为一个集函数,将每个顶点的边的特征进行综合
$g^t(·)$ 更新顶点i的特征
在本文中,顶点的特征 $v_i$,就是之前所说的每个点的状态 $s_i$
在本文新的迭代更新方程被提出,但我不理解其中的意义,文章说这样的更新是为了增加translation invariance
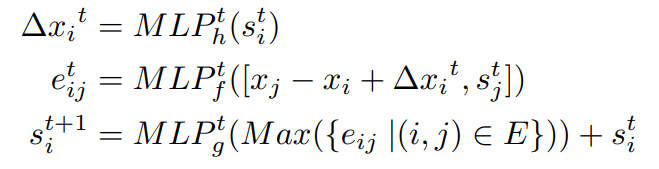
LOSS
We use the average cross-entropy loss as the classification loss.
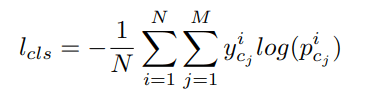
We encode the bounding box with the vertex coordinates (xv, yv, zv) as follows:
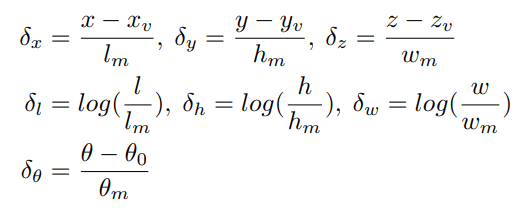
We then average the localization loss of all the vertices:
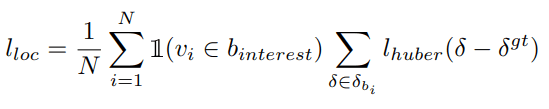
To prevent over-fitting, we add L1 regularization to each MLP. The total loss is then:
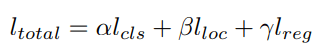
Box Merging and Scoring
文章通过一些的方法来实现近似于(更好于)NMS的效果,我没有仔细看
Eperiment
最终实验结果还是很不错的
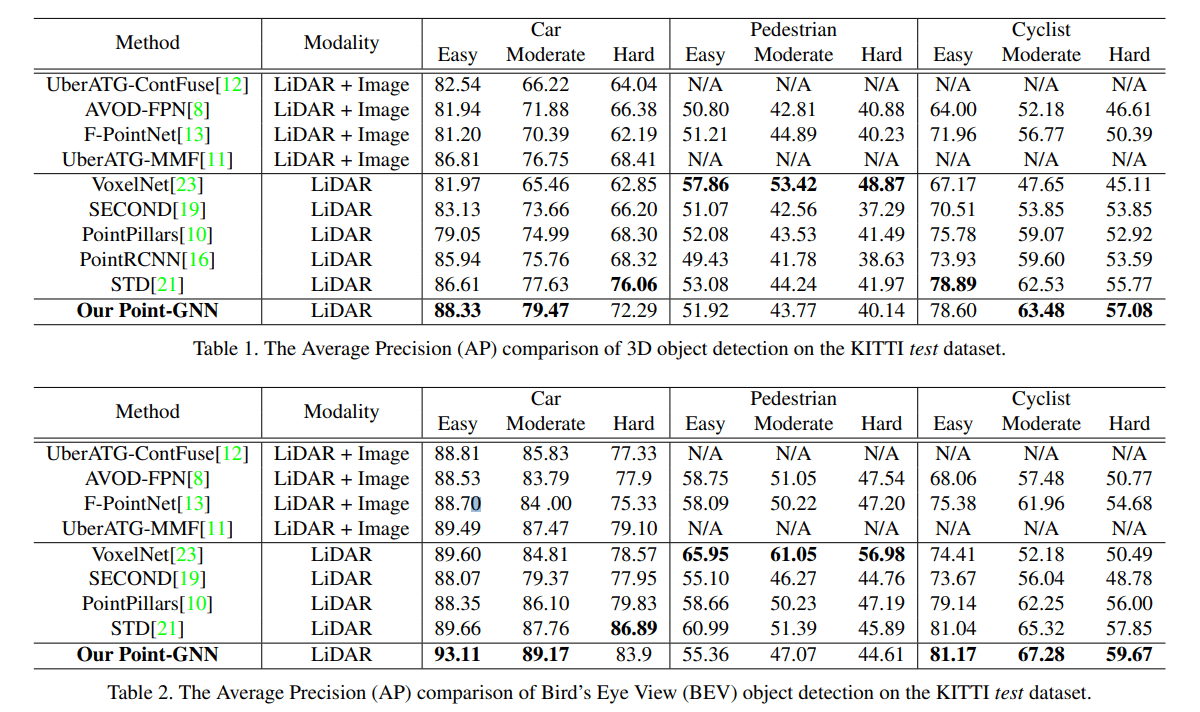
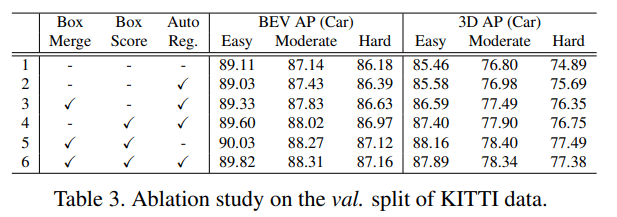
感觉比较简单的设计但达到了较好的效果,也不清楚这个网络的表现好到底来源于哪一部分…
不作为今后延申的重点,持观望态度


